GlusterFS
Introdução
O GlusterFS (Gluster File System ou Sistema de Arquivo Gluster), é um sistema de arquivos distribuído e de código aberto projetado para escalabilidade, desempenho e confiabilidade. Ele foi desenvolvido pela Gluster Inc. e, posteriormente, adquirido pela Red Hat.
O GlusterFS é usado para juntar vários servidores, com o intuito de criar um grande espaço de armazenamento. Essa é uma das características mais importantes do GlusterFS, a capacidade de armazenar dados de forma redundante, distribuindo cópias dos dados em servidores distintos para aumentar a confiabilidade e a tolerância a falhas.
O GlusterFS oferece a opção de replicar dados entre os servidores. Isso significa que, se um servidor falhar, os dados ainda estarão disponíveis em outros servidores que têm cópias dos mesmos dados. Essa redundância é valiosa para garantir a integridade e a disponibilidade dos dados em ambientes distribuídos.
Principais características do GlusterFS:
Escalabilidade Horizontal
Pode ser facilmente escalado adicionando mais nós ao cluster, permitindo acomodar grandes volumes de dados.Redundância e Tolerância a Falhas
Fornece opções para replicar dados entre diferentes servidores para garantir a redundância e tolerância a falhas.Desempenho
O GlusterFS é projetado para oferecer bom desempenho em ambientes distribuídos, com a capacidade de distribuir o tráfego de leitura e gravação entre os nós do cluster.Integração com Virtualização
Pode ser integrado a ambientes de virtualização, como o ambiente de virtualização Red Hat Virtualization (oVirt) ou o ambiente de virtualização baseado no kernel (KVM).Acesso através de Protocolos Padrão
É possível usar o NFS tradicional, SMB/CIFS para clientes Windows ou o próprio GlusterFS nativo (alguns pacotes adicionais são necessários nas máquinas clientes para isso).
O GlusterFS é uma solução robusta para casos de uso que exigem armazenamento distribuído e compartilhado, e é frequentemente utilizado em ambientes de nuvem, virtualização e grandes infraestruturas de dados.
File System
O File System (ou Sistema de Arquivo em português) é uma uma estrutura de dados que fornece uma maneira de gerenciar os dados dentro das partições de dispositivos de armazenamento ou no disco inteiro (caso não seja particionado). Cabe ao Sistema Operacional fazer essa gerencia dos dados usando o File System correto.
Como o GlusterFS funciona?
Um volume Gluster são servidores que fazem parte de um grupo de servidores de armazenamento que operam juntos para fornecer uma solução robusta e confiável, os servidores incluídos nesse conjunto colaboram para formar o volume Gluster, compartilhando e gerenciando o armazenamento de maneira coordenada. Em cada servidor, há um programa de gerenciamento (glusterd) que supervisiona um processo de bloco (glusterfsd).
Esse processo de bloco, por sua vez, compartilha o armazenamento em disco subjacente (File System que está em uso no disco). Quando um cliente se conecta, ele monta o volume, tornando o armazenamento de todos os blocos acessível como se fosse um único espaço de armazenamento para as aplicações. Tanto o cliente quanto o processo de bloco possuem diferentes "tradutores" que ajudam a direcionar as operações de entrada e saída das aplicações para os blocos apropriados. Esses tradutores desempenham um papel fundamental na comunicação eficiente entre os servidores.
Tipos de Volumes
O GlusterFS suporta alguns tipos de volumes, são eles:
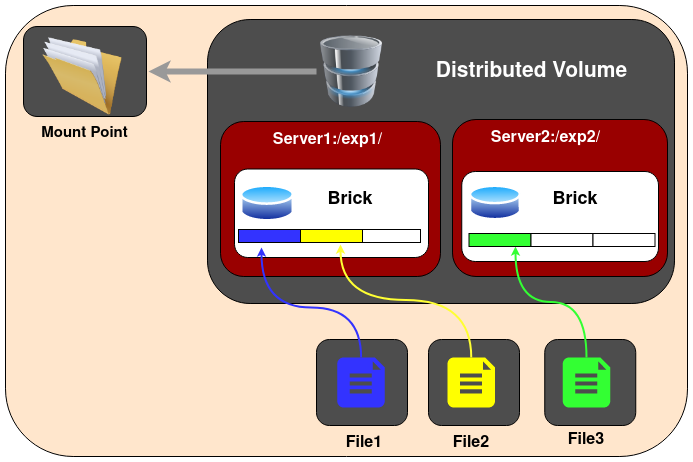
Volume Distribuído
Este é o tipo de volume criado por padrão se nenhum tipo de volume for especificado. Os arquivos são distribuídos entre vários blocos no volume, o dado1 pode ser armazenado apenas no bloco1 ou bloco2, mas não em ambos, portanto, não há redundância de dados. Isso também significa que uma falha em um bloco resultará na perda completa de dados, e é necessário confiar no hardware subjacente para a proteção contra perda de dados.
O propósito desse volume de armazenamento é escalar facilmente e de forma econômica o tamanho do volume.
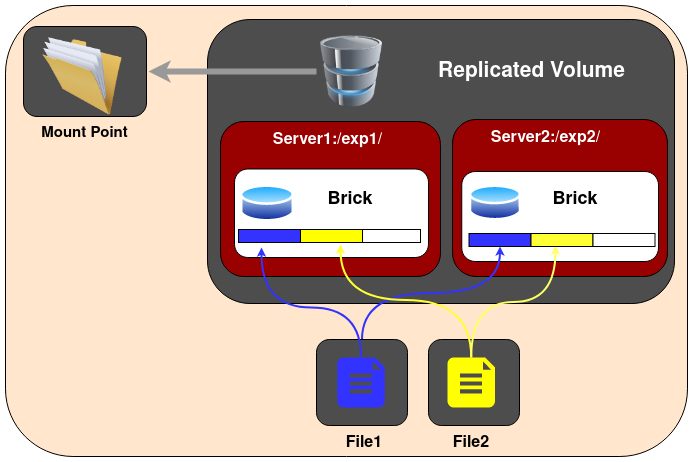
Volume Replicado
Nesse tipo de volume são mantidas cópias exatas dos dados em todos os blocos. O número de réplicas no volume pode ser decidido pelo cliente ao criar o volume. É necessário ter pelo menos dois blocos para criar um volume com 2 réplicas ou um mínimo de três blocos para criar um volume com 3 réplicas. Uma grande vantagem de tal volume é que, mesmo se um bloco falhar, os dados ainda podem ser acessados a partir de seus blocos replicados.
Esse tipo de volume é usado para melhor confiabilidade e redundância de dados.
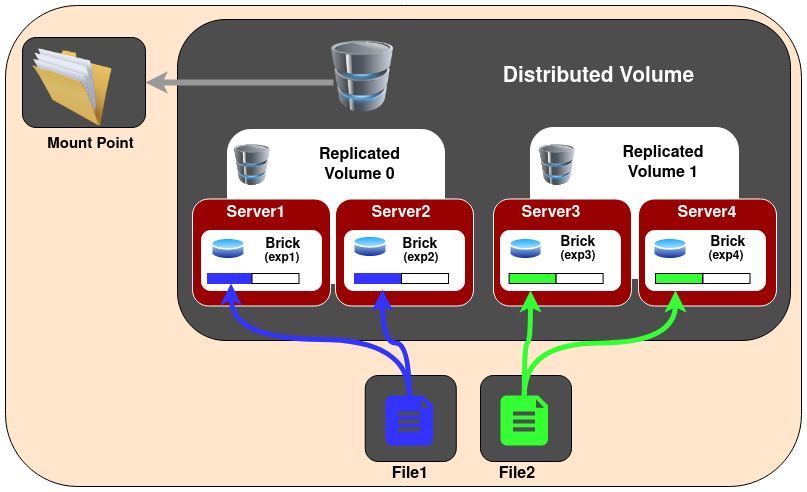
Volume Distribuído Replicado
Neste tipo de volume, os arquivos são distribuídos entre conjuntos replicados de blocos. O número de blocos deve ser um múltiplo do número de réplicas. Além disso, a ordem na qual especificamos os blocos é importante, pois blocos adjacentes se tornam réplicas um do outro.
Esse tipo de volume é usado quando é necessário alta disponibilidade de dados devido à redundância e escalabilidade de armazenamento. Portanto, se houver oito blocos e uma contagem de réplicas de 2, os dois primeiros blocos se tornam réplicas um do outro, depois os dois seguintes, e assim por diante.
Esse volume é representado como 4x2. Da mesma forma, se houver oito blocos e uma contagem de réplicas de 4, quatro blocos se tornam réplicas uns dos outros, e denotamos esse volume como um volume 2x4. Para simplificar, ele é a junção entre Volume Distribuído e Volume Replicado.
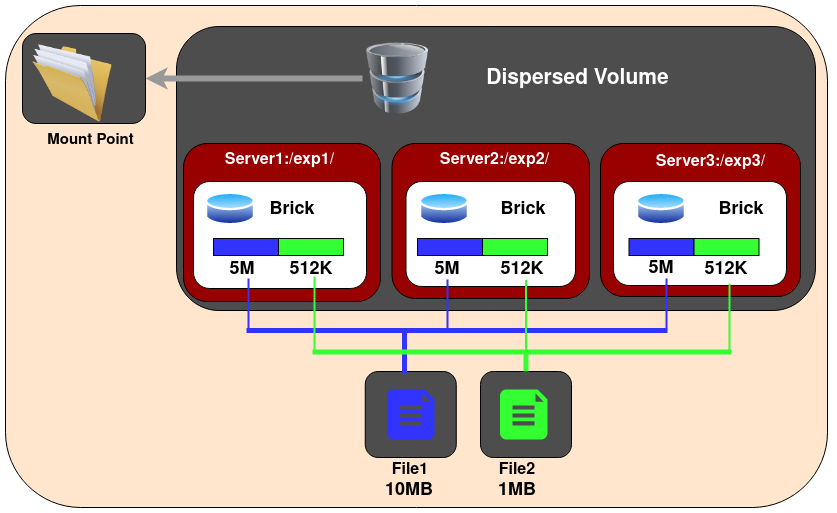
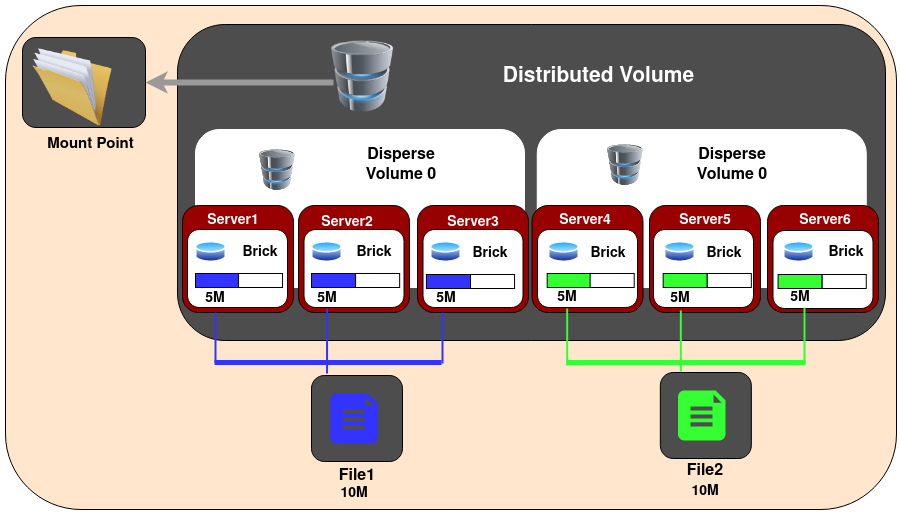
Volume Disperso
Volumes dispersos são baseados em códigos de apagamento (erasure codes). Eles distribuem os dados codificados dos arquivos, com alguma redundância adicionada, entre vários blocos no volume. Você pode usar volumes dispersos para ter um nível configurável de confiabilidade com um mínimo de desperdício de espaço. O número de blocos redundantes no volume pode ser decidido pelos clientes ao criar o volume. Blocos redundantes determinam quantos blocos podem ser perdidos sem interromper a operação do volume.
Volume Distribuído Disperso
Volumes dispersos distribuídos são equivalentes a volumes distribuídos replicados, mas usam sub-volumes dispersos em vez de replicados. O número de blocos deve ser um múltiplo do primeiro sub-volume. O propósito desse tipo de volume é escalar facilmente o tamanho do volume e distribuir a carga entre vários blocos.
FUSE - File System in Userspace
O GlusterFS é um sistema de arquivos que opera no espaço de usuário. Essa abordagem foi necessária para evitar a necessidade de ter módulos no kernel do Linux. Como é um sistema de arquivos em espaço de usuário, para interagir com o VFS (Virtual File System) do kernel, o GlusterFS faz uso do FUSE (File System in Userspace).
O FUSE é um módulo do kernel que suporta a interação entre o VFS do kernel e aplicativos de usuário não privilegiados, e ele possui uma API que pode ser acessada a partir do espaço de usuário. Usando essa API, qualquer tipo de sistema de arquivos pode ser escrito em quase qualquer linguagem de sua preferência, já que existem muitas conexões entre o FUSE e outras linguagens.

A comunicação entre o módulo FUSE do kernel e a biblioteca FUSE (libfuse) é feita por meio de um descritor de arquivo especial obtido ao abrir /dev/fuse. Este arquivo pode ser aberto várias vezes, e o descritor de arquivo obtido é passado para a chamada de sistema de montagem (mount syscall), para associar o descritor com o sistema de arquivos montado.
VFS - Virtual File System
O Sistema de Arquivos Virtual do Kernel é como um assistente que ajuda o Linux a organizar e encontrar todos os seus arquivos. Imagine que o seu Linux é como uma caixa organizadora com muitos arquivos diferentes dentro dela. Agora, cada um dos arquivos precisa de um lugar especial onde pode ser guardado e lembrado. O VFS é como um catálogo que ajuda o Linux a saber onde cada arquivo está na caixa. Ele organiza tudo para que, quando você quiser achar algo específico (como abrir um arquivo), o Linux saiba exatamente onde encontrá-lo.
O VFS opera no kernel do sistema operacional. O kernel é a parte central do sistema operacional, responsável por gerenciar os recursos do hardware e fornecer uma interface para que os programas (ou aplicativos) possam interagir com o hardware. O VFS desempenha um papel crucial na abstração e gerenciamento dos sistemas de arquivos. Ele fornece uma camada comum para os diferentes tipos de sistemas de arquivos, permitindo que o sistema operacional trabalhe com diversos formatos de armazenamento sem que os programas precisem se preocupar com as especificidades de cada um.
Funcionamento geral do GlusterFS
Assim que o GlusterFS é instalado em um nó do servidor, um binário do daemon de gerenciamento do Gluster (glusterd) será criado. Esse daemon deve estar em execução em todos os nós participantes do cluster. Após iniciar o glusterd, é possível criar um conjunto de servidores confiáveis (TSP, Trusted Server Pool) composto por todos os nós do servidor de armazenamento (o TSP pode incluir até mesmo um único nó). Agora, bricks, que são as unidades básicas de armazenamento (diretório dentro do cluster), podem ser criados como diretórios de exportação nesses servidores. Qualquer número de bricks deste TSP pode ser agrupado para formar um volume.
Uma vez que um volume é criado, um processo glusterfsd começa a ser executado em cada brick (dispositivo de armazenamento) participante. Juntamente com isso, arquivos de configuração conhecidos como arquivos de volume (vol) serão gerados dentro de /var/lib/glusterd/vols/. Haverá arquivos de configuração correspondentes a cada brick no volume. Isso conterá todos os detalhes sobre aquele brick específico. O arquivo de configuração necessário para um processo cliente também será criado. Depois desse processo todo podemos montar este volume em uma máquina cliente da seguinte forma e usá-lo como usamos um armazenamento local:
mount.glusterfs <IP ou nome do host>:<nome_do_volume> <ponto_de_montagem>
O IP ou nome do host pode ser o de qualquer nó no conjunto de servidores confiáveis no qual o volume necessário foi criado. Quando montamos o volume no cliente, o processo glusterfs do cliente se comunica com o processo glusterd dos servidores. O processo glusterd do servidor envia um arquivo de configuração (arquivo de volume) contendo a lista de translator do cliente e outro contendo as informações de cada brick no volume, agora o processo glusterfs do cliente pode se comunicar diretamente com o processo glusterfsd de cada brick. A configuração está agora completa e o volume está pronto para o serviço do cliente.
Princípios Gerais de Configuração
Vamos entender alguns conceitos-chave que estão envolvidos no GlusterFS. Primeiro, é importante entender que o GlusterFS não é realmente um sistema de arquivos em si. Ele concatena sistemas de arquivos existentes em um (ou mais) blocos grandes para que os dados gravados ou lidos no Gluster sejam distribuídos simultaneamente por vários hosts. Isso significa que você pode usar espaço de qualquer host que esteja disponível. Normalmente, o XFS é recomendado, mas também pode ser usado com outros sistemas de arquivos, como o EXT4.
Agora que entendemos isso, podemos definir alguns dos termos comuns usados no Gluster.
Um trusted pool refere-se a um cluster Gluster confiável. Em resumo podemos pensar apenas como um Cluster.
Um node refere-se a qualquer servidor que faça parte de um trusted pool. Em geral, isso pressupõe que todos os nodes estão no mesmo trusted pool.
Um brick é comumente utilizado para se referir a um diretório em um servidor específico dentro do cluster. Esse diretório é parte do espaço de armazenamento distribuído e é usado pelo GlusterFS para distribuir e replicar dados.
Um export refere-se ao caminho de montagem do(s) brick(s) em um determinado servidor, por exemplo,
/export/brick1.O termo Global Namespace é uma maneira sofisticada de dizer um volume Gluster.
Um Gluster volume é uma coleção de um ou mais bricks (é claro, tipicamente são dois ou mais). Isso é análogo às entradas
/etc/exportspara o NFS.GNFS e kNFS. GNFS é como nos referimos ao servidor NFS embutido do Gluster. kNFS significa NFS do kernel, ou, NFS simples. Na maioria das vezes, você vai querer desativar os serviços kNFS nos nós Gluster. O NFS do Gluster (GNFS) não requer configuração adicional e funciona exatamente como você esperaria com o NFSv3. É possível configurar o Gluster e o NFS para coexistirem harmoniosamente, se desejar.
Para simplificar o entendimento de como funciona o GlusterFS veja a imagem abaixo:
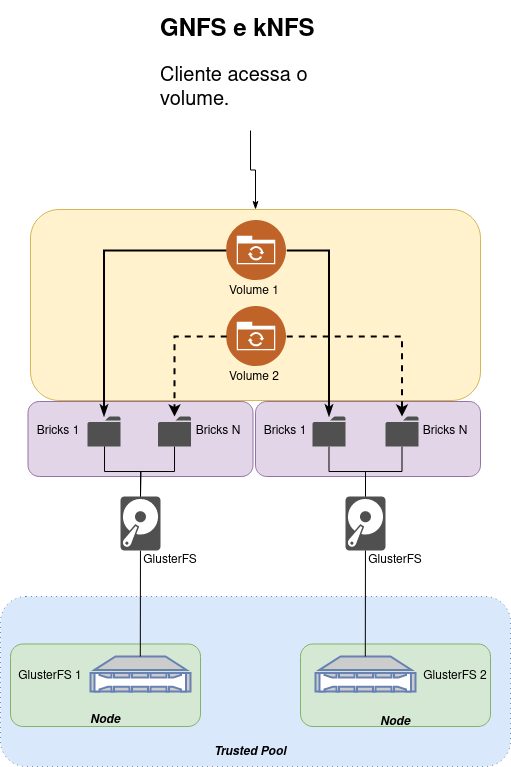
No GlusterFS, a estrutura hierárquica é organizada da seguinte forma:
O Trusted Pool é o nível mais alto e representa o conjunto de servidores (Nodes) que compõem o cluster GlusterFS (É o agrupamento de todos os nós no cluster). Os Nodes ficam dentro do Trusted Pool, você tem os Nodes individuais que participam do cluster. Cada node é uma máquina física ou virtual no seu ambiente. Já os Bricks ficam dentro de cada node. Cada "brick" é um diretório dentro do HD/SSD que foi reservado para ser usado pelo GlusterFS. Os Volumes são formados pela agregação de "bricks", ou seja, é a junção de um Brick dentro de dois ou mais Nodes.
Ao criar um volume, você especifica quais "bricks" fazem parte desse volume. Os volumes podem ter diferentes tipos, como distribuído, replicado, distribuído replicado, etc., dependendo dos requisitos de armazenamento e redundância. É possível ter um volume com apenas um único brick, no entanto, tenha em mente que, ao ter apenas um brick, você pode não obter os benefícios completos de escalabilidade e tolerância a falhas oferecidos pelo GlusterFS, já que não haverá replicação ou distribuição de dados.
GlusterFS no Cliente
O cliente pode acessar os volumes do Gluster de várias maneiras. Podendo utilizar o método Gluster Native Client para alta concorrência, desempenho e failover transparente em clientes GNU/Linux. Também pode usar o NFSv3 para acessar os volumes do Gluster (Sem ter que instalar nada no cliente).
É possível usar o CIFS para acessar volumes ao utilizar o Microsoft Windows, bem como clientes SAMBA. Para este método de acesso, os pacotes do Samba precisam estar presentes no lado do cliente.
Gluster Native Client
O Gluster Native Client é um cliente baseado em FUSE que roda no espaço do usuário. Ele é o método recomendado para acessar volumes quando é necessário lidar eficientemente com múltiplos acessos simultâneos e alto desempenho para gravação.
Certifique-se de que as portas TCP e UDP 24007 e 24008 estejam abertas em todos os servidores Gluster. Além dessas portas, você precisa abrir uma porta para cada "brick" a partir da porta 49152 (em vez de 24009 em diante, como nas versões anteriores). O esquema de atribuição de portas para "bricks" agora está em conformidade com as diretrizes da IANA. Por exemplo: se você tiver cinco "bricks", será necessário abrir as portas de 49152 a 49156.
A partir do Gluster-10, as portas para "bricks" serão randomizadas. Uma porta é selecionada aleatoriamente dentro do intervalo da porta base até a porta máxima, conforme definido no arquivo glusterd.vol, e então atribuída ao "brick". Por exemplo: se você tiver cinco "bricks", será necessário ter pelo menos 5 portas abertas dentro do intervalo definido pela porta base (option base-port em glusterd.vol) e porta máxima (option max-port em glusterd.vol). Para reduzir o número de portas abertas (para as melhores práticas de segurança), é possível diminuir o valor da porta máxima no arquivo glusterd.vol e reiniciar o glusterd para que as alterações tenham efeito.
Você pode usar as seguintes chains com o iptables:
sudo iptables -A RH-Firewall-1-INPUT -m state --state NEW -m tcp -p tcp --dport 24007:24008 -j ACCEPT
sudo iptables -A RH-Firewall-1-INPUT -m state --state NEW -m tcp -p tcp --dport 49152:49156 -j ACCEPT
NFS v3
É possível usar o NFS v3 nativo do Unix/Linux para acessar os volumes do Gluster. O GlusterFS agora inclui o Network Lock Manager (NLM) v4. O NLM permite que aplicativos em clientes NFSv3 realizem bloqueios de registros em arquivos no servidor NFS. Ele é iniciado automaticamente sempre que o servidor NFS é executado.
CIFS
Você pode usar o CIFS para acessar os volumes ao utilizar o Microsoft Windows, bem como clientes SAMBA. Para este método de acesso, os pacotes do Samba precisam estar presentes no lado do cliente. Você pode exportar o ponto de montagem do GlusterFS como a exportação do Samba e, em seguida, montá-lo usando o protocolo CIFS.
O acesso CIFS usando o Finder do Mac OS X não é suportado. No entanto, você pode usar a linha de comando do Mac OS X para acessar volumes do Gluster usando CIFS.
É Recomendado o uso do Samba para exportar volumes do Gluster através do protocolo CIFS. Para exportar volumes através do protocolo CIFS, primeiro monte o volume do Gluster, depois configure o Samba para exportar o ponto de montagem do volume do Gluster. Por exemplo, se um volume do Gluster estiver montado em /mnt/gluster, você deve editar o arquivo smb.conf para permitir a exportação por meio do CIFS. Abra o arquivo smb.conf em um editor e adicione as seguintes linhas para uma configuração simples:
[glustertest]
comment = For testing a Gluster volume exported through CIFS
path = /mnt/glusterfs
read only = no
guest ok = yes
Salve as alterações e inicie o serviço smb. Os passos acima são necessários para realizar múltiplas montagens. Se você deseja apenas a montagem do Samba, então no seu smb.conf você precisa adicionar:
kernel share modes = no
kernel oplocks = no
map archive = no
map hidden = no
map read only = no
map system = no
store dos attributes = yes
Para conseguir montar de qualquer servidor que esteja no trusted storage pool, deve-se repetir essas etapas em cada node do Gluster.
Reequilibrando Volumes
Depois de expandir um volume usando o comando add-brick, pode ser necessário reequilibrar os dados entre os servidores, isso significa que vamos replicar os dados entre os servidores (bricks) ou rebalancear quando o volume é distribuído; Novos diretórios criados após a expansão ou redução do volume serão distribuídos automaticamente de forma equitativa. Para todos os diretórios existentes, a distribuição pode ser corrigida reequilibrando o layout e/ou os dados.
Esta seção descreve como reequilibrar volumes GlusterFS em seu ambiente de armazenamento, usando os seguintes cenários comuns:
Fix-Layout Corrige o layout para usar a nova topologia do volume para que os arquivos possam ser distribuídos para os nós recém-adicionados.
Fix-Layout e Migrate-Data Reequilibra o volume corrigindo o layout para usar a nova topologia do volume e migrando os dados existentes.
Reequilibrando o Volume para Corrigir Mudanças no Layout
Corrigir o layout é necessário porque a estrutura do layout é estática para um diretório específico. Mesmo depois que novos blocos são adicionados ao volume, os arquivos recém-criados em diretórios existentes ainda serão distribuídos apenas entre os blocos originais. O comando gluster volume rebalance <volume_name> fix-layout start corrige as informações de layout para que os arquivos possam ser criados nos blocos recém-adicionados. Quando este comando é emitido, todas as informações de estatísticas de arquivos que já estão em cache serão revalidadas.
A partir do GlusterFS 3.6, a atribuição de arquivos aos blocos levará em consideração os tamanhos dos blocos. Por exemplo, um bloco de 20 TB receberá o dobro de arquivos de um bloco de 10 TB. Nas versões anteriores à 3.6, os dois blocos eram tratados como iguais, independentemente do tamanho, e teriam uma distribuição igual de arquivos.
Uma reorganização de layout somente corrigirá as mudanças de layout e não migrará dados. Se você deseja migrar os dados existentes, use o comando gluster volume rebalance <volume> start para reequilibrar os dados entre os servidores.
Para reequilibrar um volume para corrigir o layout:
$ sudo gluster volume rebalance <volume_name> fix-layout start
Reequilibrando o Volume para Corrigir o Layout e Migrar Dados
Depois de expandir um volume usando o comando add-brick, é necessário reequilibrar os dados entre os servidores. Um comando remove-brick acionará automaticamente um reequilíbrio.
Para reequilibrar um volume para corrigir o layout e migrar os dados existentes:
Inicie a operação de reequilíbrio em qualquer servidor:
$ sudo gluster volume rebalance <volume_name> start
Um operação de reequilíbrio tentará equilibrar o uso do disco entre os nós, portanto, ela pulará arquivos onde a movimentação resultará em um volume menos equilibrado. Isso leva a arquivos de links que ainda são deixados para trás no sistema e, portanto, pode causar problemas de desempenho. O comportamento pode ser anulado com o argumento force.
Exibindo o Status da Operação de Reequilíbrio
Você pode exibir as informações de status sobre a operação de reequilíbrio do volume, conforme necessário. Verifique o status da operação de reequilíbrio usando o seguinte comando:
$ sudo gluster volume rebalance <volume_name> status
O tempo para concluir a operação de reequilíbrio depende do número de arquivos no volume, juntamente com os tamanhos correspondentes dos arquivos. Continue verificando o status de reequilíbrio, verificando se o número de arquivos reequilibrados ou o total de arquivos escaneados continua aumentando.
Parando uma Operação de Reequilíbrio em Andamento
Você pode parar a operação de reequilíbrio, se necessário. Pare a operação de reequilíbrio usando o seguinte comando:
$ sudo gluster volume rebalance <volume_name> stop
Split brain
Split brain é uma situação em que duas ou mais cópias replicadas de um arquivo se tornam divergentes. Quando um arquivo está em split brain, há uma inconsistência nos dados ou metadados do arquivo entre os blocos de uma réplica e não há informações suficientes para escolher autoritativamente uma cópia como sendo íntegra e corrigir as cópias corrompidas, apesar de todos os blocos estarem ativos e online. Para um diretório, também existe uma situação de split brain, onde um arquivo dentro dele pode ter gfid/file-type diferentes entre os blocos de uma réplica. O split brain pode ocorrer principalmente por dois motivos:
Desconexão de rede:
- Um cliente perde temporariamente a conexão com os blocos.
- Exemplo: Par de réplicas com 2 blocos, bloco1 no servidor1 e bloco2 no servidor2.
- Cliente1 perde a conexão com bloco2, e o Cliente2 perde a conexão com bloco1 devido a uma divisão de rede.
- Gravações do Cliente1 vão para bloco1, e do Cliente2 vão para bloco2, resultando em split brain.
Falha nos processos dos blocos do Gluster ou erros:
- Exemplo: Server1 está fora e Server2 está online, gravações ocorrem no Server2.
- Server1 volta, Server2 fica fora (não ocorreu a cura / dados no Server2 não foram replicados no Server1), gravações ocorrem no Server1.
- Server2 volta: Ambos Server1 e Server2 têm dados independentes um do outro.
Prevenção e Solução:
- Se for utilizado um volume com réplica 2, não é possível evitar o split brain sem perder a disponibilidade.
- Formas de lidar com o split brain:
- Réplica 3 volume
- Volume com árbitro (Arbiter volume)
- Ambos utilizam a opção
client-quorumdo glusterfs para evitar situações de split brain.
O documento a seguir explica o uso de informações de recuperação de volume e comandos de resolução de cérebro dividido.
Client quorum
O "Client Quorum" é uma funcionalidade implementada no módulo de Replicação Automática de Arquivos (AFR), para prevenir situações de split-brain no caminho de E/S para volumes replicados ou distribuídos-replicados. Por padrão, se o client-quorum não for atendido para uma subunidade de réplica específica, ela se torna somente leitura. As outras subunidades (em um volume distribuído-replicado) ainda terão acesso de leitura e gravação.
Client Quorum em volumes de réplica 2
Em um volume de réplica 2, não é possível alcançar alta disponibilidade e consistência ao mesmo tempo, sem sacrificar a tolerância à partição. Se a opção client-quorum for definida como automática (auto), então o primeiro bloco deve estar sempre ativo, independentemente do status do segundo bloco. Se apenas o segundo bloco estiver ativo, a subunidade se torna somente leitura. Se o tipo de quorum for definido como fixo (fixed) e o número de quorum (quorum-count) for definido como 1, podemos acabar em split brain:
- Bloco1 está ativo e Bloco2 está inativo. O quorum é atendido e a gravação ocorre em Bloco1.
- Bloco1 fica inativo e Bloco2 fica ativo (nenhuma cura ocorreu). O quorum é atendido, e a gravação ocorre em Bloco2.
- Bloco1 volta a ficar ativo. O quorum é atendido, mas ambos os blocos têm gravações independentes; ocorre split brain.
Para evitar isso, é necessário definir o "quorum-count" como 2, o que terá um custo para a disponibilidade. Mesmo se tivermos um bloco de réplica em funcionamento, o quorum não é atendido, e acabamos vendo EROFS (sistema de arquivos somente leitura).
Volume de Réplica 3
Ao criar um volume replicado ou distribuído replicado com um número de réplicas de 3, a opção cluster.quorum-type é definida como automática por padrão. Isso significa que pelo menos 2 blocos devem estar ativos e em execução para satisfazer o quorum e permitir gravações. Esta é a configuração recomendada para um volume de réplica 3 e não deve ser alterada. Veja como isso impede que os arquivos acabem em split brain:
- B1, B2 e B3 são os 3 blocos de um volume de réplica 3.
- B1 e B2 estão ativos, e B3 está inativo. O quorum é atendido, e a gravação ocorre em B1 e B2.
- B3 volta a ficar ativo, e B2 fica inativo. O quorum é atendido, e a gravação ocorre em B1 e B3.
- B2 volta a ficar ativo, e B1 fica inativo. O quorum é atendido. Mas quando uma solicitação de gravação ocorre, o AFR vê que B2 e B3 estão culpando um ao outro (B2 diz que algumas gravações estão pendentes em B3, e B3 diz que algumas gravações estão pendentes em B2), portanto, a gravação não é permitida e falha com EIO.
# Comando para criar um volume de réplica 3:
gluster volume create volume_name replica 3 host1:brick1 host2:brick2 host3:brick3
Arbiter volume
O volume arbiter oferece uma solução intermediária entre replicação 2 e replicação 3, quando o usuário deseja a proteção contra split brain oferecida pela replicação 3, mas não quer investir em 3 vezes o espaço de armazenamento. O arbiter também é um volume de replicação 3, onde o terceiro bloco da réplica é automaticamente configurado como um node árbitro. Isso significa que o terceiro bloco armazena apenas o nome do arquivo e metadados, mas não armazena dados. Isso ajuda a evitar o split brain, proporcionando o mesmo nível de consistência que um volume de replicação 3 normal.
# Comando para criar um volume arbiter:
gluster volume create <volume_name> replica 3 arbiter 1 host1:brick1 host2:brick2 host3:brick3
A única diferença no comando é que precisamos adicionar mais uma palavra-chave, arbiter 1, após o número de réplicas. Como é também um volume de replicação 3, a opção cluster.quorum-type é definida como automática por padrão, e pelo menos 2 blocos devem estar ativos para satisfazer o quorum e permitir gravações. Como o bloco árbitro contém apenas o nome e os metadados dos arquivos, existem algumas verificações adicionais para garantir a consistência. O árbitro funciona da seguinte maneira:
- Os clientes fazem bloqueios de arquivo completos durante a gravação (a replicação 3 faz bloqueios de intervalo).
- Se 2 blocos estiverem ativos e se um deles for o bloco árbitro e culpar o outro bloco ativo, todas as FOPs falharão com ENOTCONN (o ponto de extremidade de transporte não está conectado). Se o árbitro não culpar o outro bloco, as FOPs serão permitidas.
- Se 2 blocos estiverem ativos e o árbitro estiver inativo, então as FOPs serão permitidas.
- Se apenas um bloco estiver ativo, então o "client-quorum" não será atendido, e o volume se tornará EROFS (sistema de arquivos somente leitura).
- Em todos os casos, se houver apenas uma fonte antes de iniciar a FOP e se a FOP falhar nessa fonte, a aplicação receberá ENOTCONN.
Diferenças entre Volumes de Réplica 3 e Arbiter
Armazenamento de Dados:
- No caso de um volume de réplica 3, armazenamos o arquivo completo em todos os blocos, e é recomendado ter blocos do mesmo tamanho.
- No caso do árbitro, como não armazenamos dados, o tamanho do bloco árbitro é comparativamente menor do que o dos outros blocos.
Natureza Intermediária:
- O árbitro é um estado intermediário entre um volume de réplica 2 e um volume de réplica 3. Se tivermos apenas o árbitro e um dos outros blocos estiver ativo, e o bloco árbitro culpar o outro bloco, então não podemos prosseguir com as FOPs.
Disponibilidade:
- A réplica 3 oferece maior disponibilidade em comparação com o árbitro, porque, ao contrário do árbitro, a réplica 3 tem uma cópia completa dos dados em todos os 3 blocos.
Self-Heal na replicação
Antigamente no módulo de replicação era necessário acionar manualmente uma self-heal (auto-cura) quando um bloco saía do ar e voltava online para sincronizar todas as réplicas. Agora, o daemon proativo de self-heal é executado em segundo plano, diagnostica problemas e inicia automaticamente a self-heal a cada 10 minutos nos arquivos que precisam de cura.
Você pode visualizar a lista de arquivos que precisam de cura, a lista de arquivos que estão atualmente/já foram curados, a lista de arquivos que estão em estado de split-brain dividido, e você pode acionar manualmente a self-heal em todo o volume ou apenas nos arquivos que precisam de cura.
Visualizar a lista de arquivos que precisam de cura:
$ sudo gluster volume heal <NOME_DO_VOLUME> info
Acionar a self-heal apenas nos arquivos que precisam de cura:
$ sudo gluster volume heal <NOME_DO_VOLUME>
Acionar a self-heal em todos os arquivos de um volume:
$ sudo gluster volume heal <NOME_DO_VOLUME> full
Veja a lista de arquivos que são auto-reparáveis:
$ sudo gluster volume heal <volume_name> info healed
Veja a lista de arquivos de um volume específico nos quais a autocorreção falhou:
$ sudo gluster volume heal <volume_name> info failed
Veja a lista de arquivos de um volume específico que estão em estado de cérebro dividido:
$ sudo gluster volume heal <volume_name> info split-brain
Trash Translator
O Translator de lixeira permitirá que os usuários acessem arquivos excluídos ou truncados. Cada bloco manterá um diretório oculto chamado trashcan, que será usado para armazenar os arquivos excluídos ou truncados do respectivo bloco. A agregação de todos esses diretórios .trashcan pode ser acessada a partir do ponto de montagem. Para evitar colisões de nomes, um carimbo de data e hora é anexado ao nome original do arquivo enquanto ele está sendo movido para o diretório de lixeira.
Além do caso de uso principal de acessar arquivos excluídos ou truncados pelo usuário, o translator de lixeira pode ser útil para operações internas, como auto-cura e rebalanceamento. Durante a auto-cura e o rebalanceamento, é possível perder dados cruciais. Nessas circunstâncias, o translator de lixeira pode ajudar na recuperação dos dados perdidos. O translator de lixeira é projetado para interceptar operações unlink, truncate e ftruncate, armazenar uma cópia do arquivo atual no diretório de lixeira e, em seguida, realizar a operação no arquivo original. Para as operações internas, os arquivos são armazenados sob a pasta internal_op dentro do diretório de lixeira.
O comando abaixo pode ser usado para habilitar um translator de lixeira em um volume. Se definido como "on", um diretório de lixeira será criado em cada bloco dentro do volume durante o comando de inicialização do volume. Por padrão, um translator é carregado durante a inicialização do volume, mas permanece não funcional. Desabilitar a lixeira com a ajuda desta opção não removerá o diretório de lixeira ou mesmo seu conteúdo do volume.
gluster volume set <volume_name> features.trash <on/off>
O comando abaixo é usado para reconfigurar o diretório de lixeira para um nome especificado pelo usuário. O argumento é um nome de diretório válido. O diretório será criado dentro de cada bloco sob este nome. Se não especificado pelo usuário, o translator de lixeira criará o diretório de lixeira com o nome padrão .trashcan. Isso só pode ser usado quando o translator de lixeira está ativado.
gluster volume set <volume_name> features.trash-dir <name>
Este comando pode ser usado para filtrar arquivos que entram no diretório de lixeira com base em seu tamanho. Arquivos acima de trash_max_filesize são excluídos/truncados diretamente. O valor para o tamanho pode ser seguido por sufixos multiplicativos como KB (=1024 bytes), MB (=10241024 bytes) e GB (=10241024*1024 bytes). O tamanho padrão é definido como 5MB.
gluster volume set <volume_name> features.trash-max-filesize <size>
O comando abaixo pode ser usado para especificar caminhos de arquivos ou diretórios que não devem ser movidos para o diretório de lixeira quando eles são excluídos ou truncados. Arquivos que residem sob esse padrão não serão movidos para o diretório de lixeira durante a exclusão/truncamento. O caminho deve ser um válido presente no volume.
gluster volume set <volume_name> features.trash-eliminate-path <path1> [ , <path2> , . . . ]
O comando abaixo pode ser usado para habilitar a lixeira para operações internas como auto-cura e rebalanceamento. Por padrão, definido como "off".
gluster volume set <volume_name> features.trash-internal-op <on/off>
Para mais detalhes acesse aqui.
Quota
As quotas de diretório no GlusterFS permitem que você defina limites no uso do espaço em disco por diretórios ou volumes. Os administradores de armazenamento podem controlar a utilização do espaço em disco nos níveis de diretório e/ou volume no GlusterFS.
Apenas limites Hard são suportados, ou seja, o limite não pode ser excedido, e as tentativas de usar mais espaço em disco ou inodes além do limite definido são negadas. Também é possível monitorar a utilização de recursos para limitar o armazenamento para os usuários
Habilitando a Quota
Antes de definir quota temos que habilitar esse recurso. Para habilitar a quota, use o seguinte comando:
gluster volume quota <volume_name> enable
Desabilitando a Quota
Para desabilitar a Quota, use o seguinte comando:
gluster volume quota <volume_name> disable
Removendo o Limite de Disco
Você pode remover o limite de disco definido se não deseja mais uma quota. Para remover o limite de disco, use o seguinte comando para remover o limite de disco definido em um diretório específico:
gluster volume quota <volume_name> remove <DIR>
Definindo ou Substituindo o Limite de Disco
Você pode criar novos diretórios em seu ambiente de armazenamento e definir o limite de disco ou definir o limite de disco para os diretórios existentes. O nome do diretório deve ser relativo ao volume, com o diretório de exportação/montagem sendo tratado como /.
Para definir ou substituir o limite de disco, use o seguinte comando:
gluster volume quota <volume_name> limit-usage <DIR> <HARD_LIMIT>
Em uma hierarquia de diretórios de vários níveis, o limite de disco mais rigoroso será considerado para a aplicação. Além disso, sempre que o limite de quota é definido pela primeira vez, um ponto de montagem auxiliar será criado em
/var/run/gluster/. Isso é semelhante a qualquer outro ponto de montagem, com algumas permissões especiais, e permanece até que a quota seja desativada.
Exibindo Informações de Limite de Disco
Você pode exibir informações de limite de disco em todos os diretórios em que o limite é definido. Para exibir informações de limite de disco, use o seguinte comando:
gluster volume quota list
Exibir informações de limite de disco em um diretório específico:
gluster volume quota list <DIR>
quota-deem-statfs
O quota-deem-statfs é uma opção no GlusterFS que afeta como as cotas de disco são aplicadas em um volume distribuído. Quando ativada, ela permite que o espaço total disponível em um diretório seja considerado como o limite rígido de quota definido para esse diretório.
Para ativar use o comando abaixo:
gluster volume set <volume_name> quota-deem-statfs on
Nesse cenário, quando você verifica as cotas usando gluster volume quota test-volume list, você verá limites rígidos e soft definidos para diferentes diretórios. No entanto, ao usar df -hT /home, o sistema de arquivos mostra o espaço total disponível no volume, mas as cotas são aplicadas conforme configurado no GlusterFS. Vejamos como isso se aplica na prática (os exemplos abaixo foram obtidos do site oficial do GlusterFS), primeiro com quota-deem-statfs desativado:
# Desative o 'quota-deem-statfs':
$ sudo gluster volume set test-volume features.quota-deem-statfs off
volume set: success
# Veja as quotas ativas:
$ sudo gluster volume quota test-volume list
Path Hard-limit Soft-limit Used Available
---------------------------------------------------------------
/ 300.0GB 90% 11.5GB 288.5GB
/John/Downloads 77.0GB 75% 11.5GB 65.5GB
Disk usage for volume test-volume as seen on client1:
# Agora veja com o comando 'DF':
$ sudo df -hT /home
Filesystem Type Size Used Avail Use% Mounted on
server1:/test-volume fuse.glusterfs 400G 12G 389G 3% /home
O exemplo a seguir exibe o uso de disco quando quota-deem-statfs está ativado:
# Desative o 'quota-deem-statfs':
$ sudo gluster volume set test-volume features.quota-deem-statfs on
volume set: success
# Veja as quotas ativas:
$ sudo gluster vol quota test-volume list
Path Hard-limit Soft-limit Used Available
-----------------------------------------------------------
/ 300.0GB 90% 11.5GB 288.5GB
/John/Downloads 77.0GB 75% 11.5GB 65.5GB
Disk usage for volume test-volume as seen on client1:
# Agora veja com o comando 'DF':
$ sudo df -hT /home
Filesystem Type Size Used Avail Use% Mounted on
server1:/test-volume fuse.glusterfs 300G 12G 289G 4% /home
Atualizando o Tamanho do Cache de Memória
A utilização de uma memória cache no cliente do GlusterFS é uma prática comum para otimizar o desempenho. Ela armazena informações, como tamanhos de diretórios, localmente no cliente para evitar consultas frequentes ao servidor. O timeout no cache é uma medida de precaução. Garante que as informações armazenadas localmente no cache sejam atualizadas periodicamente a partir do servidor para refletir alterações mais recentes no volume.
O soft timeout é aplicado quando o uso está abaixo do limite suave, enquanto que o hard timeout é aplicado quando o uso está entre o limite soft e o limite hard. O timeout é aplicado em segundos.
Para atualizar o tamanho do cache de memória, para o limite soft, use o comando abaixo:
gluster volume set <volume_name> features.soft-timeout <time>
Para atualizar o tamanho do cache de memória, para o limite hard, use o comando abaixo:
gluster volume set <volume_name> features.hard-timeout <time>
Configurando o Tempo de Alerta
O tempo de alerta é a frequência com que você deseja que suas informações de uso sejam registradas após atingir o limite soft. O tempo de alerta padrão é uma semana.
Para configurar o tempo de alerta, use o seguinte comando:
gluster volume quota <volume_name> alert-time <time>
# time = 1d (um dia)
Tuning Volume
Podemos ajustar as opções de um volume enquanto o cluster está online e disponível. O intuito de fazer o Tuning é fazer um ajuste fino ou otimização de configurações para melhorar o desempenho ou a eficiência.
É recomendado definir a opção server.allow-insecure como ON se houver muitos bricks em cada volume ou se houver muitos serviços que já utilizaram todas as portas privilegiadas do sistema. Ativar esta opção permite que as portas aceitem/rejeitem mensagens de portas inseguras. Use esta opção somente se sua implantação exigir.
Para ver as opções disponíveis acesse o site oficial.
Abaixo seguem algumas opções interessantes:
| Opção | Descrição |
|---|---|
| performance.write-behind on | Ativa a funcionalidade de gravação em segundo plano, onde os dados são gravados no disco após serem confirmados como gravados na memória, melhorando o desempenho. |
| nfs.disable on | Desativa o suporte ao protocolo NFS (Network File System). Se ativado, desabilita a exportação do volume via NFS. |
| cluster.lookup-optimize off | Desativa otimizações para pesquisa de clusters. Pode melhorar o desempenho da pesquisa de clusters em certos cenários. |
| performance.stat-prefetch off | Desativa a leitura antecipada de estatísticas para arquivos, o que pode ser útil em alguns casos de carga de trabalho. |
| server.allow-insecure on | Permite que o servidor aceite conexões de clientes considerados "inseguros". |
| storage.batch-fsync-delay-usec 0 | Configura o atraso de sincronização em lote para zero microssegundos, desativando essencialmente a sincronização em lote. |
| performance.client-io-threads off | Desativa o uso de threads no lado do cliente para operações de I/O, usando um único thread por cliente. |
| network.frame-timeout 60 | Define o tempo limite para quadros de rede (em segundos). Se não houver atividade dentro deste intervalo, a conexão pode ser encerrada. |
| performance.quick-read on | Ativa a leitura rápida para otimizar a recuperação de dados. |
| performance.flush-behind off | Desativa a operação de "flush behind", que é uma técnica de gravação otimizada. |
| performance.io-cache off | Desativa o uso de cache de I/O, o que pode ser útil em cenários específicos. |
| performance.read-ahead off | Desativa a leitura antecipada para otimizar a leitura de dados. |
| performance.cache-size 0 | Define o tamanho da cache para zero, desativando a cache. |
| performance.io-thread-count 64 | Define o número de threads de I/O para 64, otimizando operações de I/O. |
| network.ping-timeout 5 | O tempo que o cliente espera para verificar se o servidor está respondendo. Quando ocorre um tempo limite de ping, há uma desconexão de rede entre o cliente e o servidor. Todos os recursos mantidos pelo servidor em nome do cliente são limpos. Quando ocorre uma reconexão, todos os recursos precisarão ser readquiridos antes que o cliente possa retomar suas operações no servidor. |
| server.event-threads 16 | Especifica o número de threads de eventos no servidor a serem executados em paralelo. Valores maiores ajudariam a processar respostas mais rapidamente, dependendo do poder de processamento disponível. |
| transport.address-family inet6 | Habilita o uso do IPv6. |
| storage.fips-mode-rchecksum on | Ativa o cálculo de checksums em modo FIPS para segurança. |
| storage.owner-gid VALUE | Define o GID (Group ID) do proprietário do armazenamento para 121. |
| storage.owner-uid VALUE | Define o UID (User ID) do proprietário do armazenamento para 64055. |
| server.anonuid VALUE | Valor do UID usado para o usuário anônimo quando o root-squash está habilitado. Quando o root-squash está habilitado, todas as solicitações recebidas do UID root (que é 0) são alteradas para ter o UID do usuário anônimo. |
Mandatory Locks - Travas obrigatórias
Se dois nós (nodes) começarem a escrever simultaneamente no mesmo arquivo em um volume do GlusterFS sem uma gestão adequada das travas (locks), pode ocorrer uma condição de corrida, resultando em um comportamento imprevisível e possíveis corrupções de dados. Isso ocorre porque o GlusterFS, por padrão, não impõe travas obrigatórias em operações de leitura ou escrita.
Sem travas, ambos os nós podem modificar o arquivo simultaneamente, o que pode levar a inconsistências nos dados. As operações de escrita concorrentes podem interferir uma na outra, resultando em um estado de arquivo que não reflete corretamente as alterações feitas por ambos os nós.
Para evitar esse problema, pode ser configurado o GlusterFS para usar travas obrigatórias (mandatory locks). As travas obrigatórias garantem que apenas um nó por vez tenha permissão para escrever em um arquivo específico, evitando condições de corrida. No entanto, a implementação e o impacto dessa configuração podem variar dependendo da versão do GlusterFS e da configuração específica do volume.
Antes de implementar, faça testes para entender o comportamento e o impacto que isso pode trazer, as vezes nem sempre são positivos e a melhor escolher pode ser ficar sem as travas.
O suporte a "Mandatory Locks" no GlusterFS não é habilitado por padrão. O administrador pode configurar o comportamento de "Mandatory Locks" para um volume específico usando o seguinte comando:
gluster volume set <volume_name> locks.mandatory-locking <off / file / forced / optimal>
Opções disponíveis:
- off: Desativa "Mandatory Locks" para o volume.
- file: Ativa uma forma de Mandatory Locking semelhante à utilizada pelo kernel Linux. Como é uma das formas menos testada, pode haver alguns casos em que o comportamento não é totalmente previsível ou testado em todos os cenários.
- forced: Verifica travas de intervalo de bytes conflitantes para cada operação de modificação de dados em um volume.
- optimal: Modo combinacional onde clientes POSIX podem trabalhar com suas semânticas de trava consultiva, ainda respeitando as travas obrigatórias adquiridas por outros clientes como o SMB.
As configurações feitas usando gluster volume set só entram em vigor após um subsequente início/reinício do volume.
GlusterFS vs RAID
O GlusterFS e os arrays RAID (Redundant Array of Independent Disks) são soluções diferentes para alcançar redundância e tolerância a falhas em sistemas de armazenamento, inclusive é uma excelente prática aplicar redundância via RAID sempre que possível, diminuindo as chances de perda de dados. Aqui estão algumas das principais diferenças:
Arquitetura:
- GlusterFS: É um sistema de arquivos distribuído que opera em nível de software. Ele conecta vários servidores para criar um único sistema de arquivos distribuído.
- RAID: É uma tecnologia que opera em nível de hardware ou controlador RAID. Geralmente, envolve a combinação de vários discos rígidos físicos para formar uma única unidade lógica de armazenamento.
Redundância:
- GlusterFS: Alcança a redundância distribuindo cópias dos dados entre diferentes servidores no cluster. Se um servidor falhar, os dados ainda estão disponíveis em outros servidores.
- RAID: Usa diferentes níveis de RAID para redundância. RAID 1, por exemplo, espelha dados em dois discos, garantindo que, se um disco falhar, os dados ainda estejam disponíveis no disco espelhado.
Flexibilidade e Escalabilidade:
- GlusterFS: Oferece uma escalabilidade horizontal fácil, permitindo adicionar mais servidores para aumentar a capacidade. Pode ser mais flexível em ambientes distribuídos.
- RAID: A escalabilidade muitas vezes envolve a adição de mais discos ao array RAID existente. A flexibilidade pode ser mais limitada em comparação com sistemas distribuídos.
Implementação:
- GlusterFS: Implementação em nível de software, facilitando a integração em ambientes diversos.
- RAID: Pode ser implementado em nível de hardware (controlador RAID dedicado) ou em nível de software (RAID de software).
GlusterFS vs NAS
Se você estiver usando tanto um NAS quanto o GlusterFS via NFS, é possível que esteja interessado em entender como a redundância é tratada em ambos os casos quando o NFS é utilizado como protocolo de acesso aos dados. Isso acontece porque olhando de uma camada mais superficial (a nível das aplicações) parece que ambos são iguais, afinal, em ambos teremos redundância dos dados.
Redundância
- O NAS quando bem feito usa RAID para proporcionar redundância, essa redundância ocorre nos dispositivos de armazenamento e ainda pode usar um Sistemas de Arquivo como o ZFS para prover integridade de dados, Snapshot dentre outras inúmeras features. O GlusterFS, por outro lado, distribui cópias dos dados entre servidores, proporcionando redundância distribuída, é como se fizesse um RAID 1, só que para servidores diferentes; enquanto o RAID fica localizado no mesmo server, só que para dispositivos de armazenamento diferentes.
Escala e Flexibilidade:
- O GlusterFS é projetado para escalabilidade horizontal, facilitando a expansão. Se a sua necessidade é crescer de forma fácil e distribuída, o GlusterFS pode ser uma escolha forte, já que escalar em nível de hardware como num NAS pode ter questões de custos mais elevados e limitações de hardware.
Em resumo, tanto o RAID em servidores locais ou acessados via rede (NAS) quanto o GlusterFS oferecem redundância, mas em níveis diferentes.
RAID/NAS:
- O RAID, seja local no servidor GlusterFS ou em um servidor remoto acessado via rede (NAS), fornece redundância em um nível local. Isso significa que os dados são replicados ou distribuídos localmente nos dispositivos de armazenamento. Se um servidor com essa característica falhar, a disponibilidade dos dados pode ser afetada, já que a redundância está vinculada ao próprio servidor, ou seja, o acesso aos dados pode ser comprometida.
GlusterFS:
- Por outro lado, o GlusterFS introduz o conceito de redundância distribuída. Aqui, os dados são distribuídos entre servidores diferentes, não apenas em dispositivos de armazenamento, mas em servidores distintos. Isso significa que, mesmo se um servidor GlusterFS falhar, os dados ainda estão acessíveis a partir de outros servidores que mantêm cópias dos mesmos dados. Em comparação com um servidor com RAID/NAS, um problema em um servidor GlusterFS não afeta o acesso aos dados, como acontece com o RAID/NAS.
Essa abordagem distribuída do GlusterFS proporciona uma maior tolerância a falhas, pois a redundância não está centralizada em um único servidor. Entretanto, a escolha entre RAID/NAS e GlusterFS dependerá das necessidades específicas do ambiente, considerando fatores como escalabilidade, complexidade e os requisitos de redundância desejados.
GlusterFS vs iSCSI
Embora iSCSI (Internet Small Computer System Interface) e GlusterFS estejam relacionados ao armazenamento de dados em redes, eles têm propósitos e funcionalidades distintas. O iSCSI permite que servidores acessem discos rígidos via rede (são blocos de armazenamento remotos), como se estivessem conectados localmente. Já o GlusterFS conecta servidores para criar um sistema de arquivos distribuído, distribuindo cópias dos dados entre eles, diferente do iSCSI o cliente não acessa diretamente o disco rígido compartilhado pela rede e sim o File System que está sendo compartilhado pela rede.
Informações do site oficial traduzidas
Abaixo seguem alguns tópicos que julguei serem interessantes, fiz a tradução e estou disponibilizando aqui, cada tópico abaixo terá o link para que possa visualizar na íntegra.
O Gluster vai funcionar para mim e para o que eu preciso que ele faça?
Muito provavelmente, sim. As pessoas usam o Gluster para necessidades de armazenamento de uma variedade de cargas de trabalho de aplicativos. Acessar o Gluster pelo SMB/CIFS muitas vezes será lento para os padrões da maioria das pessoas. Se você apenas moderar o acesso por usuários, provavelmente não será um problema para você.
Por outro lado, adicionando servidores Gluster suficientes à mistura, algumas pessoas têm visto melhor desempenho conosco do que com outras soluções devido à natureza de escalabilidade da tecnologia. O Gluster é tradicionalmente melhor ao usar tamanhos de arquivo de pelo menos 16 KB (com um ponto ideal em torno de 128 KB ou algo assim).
OK, mas se eu adicionar servidores depois, eles não precisam ser exatamente iguais?
Em um mundo perfeito, sim. Ter o hardware igual significa menos solução de problemas quando os problemas começam a surgir. Mas muitas pessoas implantam o Gluster em hardware misto com sucesso.
Arquitetura
Alguns dos conceitos sobre a arquitetura que o Gluster usa foram mencionados acima, mas existem tópicos mais avançados que deixei para falar agora.
Translators
Um Translator (ou Tradutor) converte solicitações de usuários em solicitações de armazenamento. Por exemplo, Um para um, um para muitos, um para zero (por exemplo, cache). Isso significa que um tradutor pode lidar com diferentes relações entre as solicitações de usuários e as solicitações de armazenamento. Por exemplo, pode ser responsável por traduzir uma solicitação de usuário em várias solicitações de armazenamento ou até mesmo nenhuma solicitação, dependendo do contexto (como no caso de caching).
Um tradutor pode alterar o tipo de solicitação original durante o processo de transferência entre diferentes tradutores. Os tradutores têm a capacidade de modificar não apenas o tipo de solicitação, mas também caminhos, sinalizadores (flags) e até mesmo os dados envolvidos nas solicitações. Isso é útil em casos como criptografia, onde os dados precisam ser modificados para maior segurança.
Os tradutores podem interceptar ou bloquear as solicitações, como em casos de controle de acesso, onde determinadas operações podem ser bloqueadas com base em permissões. Também podem criar novas solicitações, isso é útil em situações como pré-busca, onde o sistema antecipa e executa solicitações antes mesmo de serem explicitamente solicitadas.
Como os Translators funcionam?
No GlusterFS, os Translators desempenham um papel crucial na comunicação entre usuários e armazenamento. Eles são implementados como objetos compartilhados carregados dinamicamente, adaptando-se conforme necessário. A configuração de ponteiros entre tradutores é feita dinamicamente, facilitando a comunicação. Durante a inicialização, os tradutores definem como manipular operações de entrada e saída (I/O) por meio de ponteiros de operações de arquivo (fops). Convenções específicas garantem a consistência na validação e passagem de opções entre tradutores. Desde a versão 3.1 do GlusterFS, a configuração dos tradutores é gerenciada pela CLI, isso simplifica o processo de configuração, eliminando a necessidade de entender a ordem exata de encadeamento dos translators.
Tipos de Translators
Lista de tradutores conhecidos com seu status atual:
| Tipo de Tradutor | Finalidade Funcional |
|---|---|
| Storage | Tradutor de nível mais baixo, armazena e acessa dados no sistema de arquivos local. |
| Debug | Fornece interface e estatísticas para erros e depuração. |
| Cluster | Lida com a distribuição e replicação de dados relacionados à gravação e leitura de blocos e nós. |
| Encryption | Tradutores de extensão para criptografia/decifragem de dados armazenados em tempo real. |
| Protocol | Tradutores de extensão para protocolos de comunicação cliente/servidor. |
| Performance | Tradutores de ajuste para adaptar-se à carga de trabalho e aos perfis de I/O. |
| Bindings | Adiciona extensibilidade, por exemplo, a interface Python escrita por Jeff Darcy para estender a interação da API com o GlusterFS. |
| System | Tradutores de acesso ao sistema, por exemplo, interagindo com o controle de acesso ao sistema de arquivos. |
| Scheduler | Schedulers de I/O que determinam como distribuir novas operações de gravação em sistemas agrupados. |
| Features | Adiciona recursos adicionais como cotas, filtros, travas, etc. |
DHT - Distributed Hash Table
DHT é a forma de como o GlusterFS agrega capacidade e desempenho em vários servidores. Sua responsabilidade é colocar cada arquivo exatamente em uma de suas subunidades; ao contrário da replicação (que coloca cópias em todas as suas subunidades) ou striping (que coloca partes em todas as suas subunidades). É uma função de roteamento, não de divisão ou cópia.
Como o DHT funciona?
O método básico usado no DHT é o hash consistente. Quando você abre um arquivo, o translator de distribuição fornece uma informação para encontrar o arquivo (o nome do arquivo). Para determinar onde está esse arquivo, o tradutor executa o nome do arquivo por meio de um algoritmo de hash, para então, transformar esse nome de arquivo em um número. Algumas observações sobre a atribuição de valores de hash DHT:
A atribuição de intervalos de hash para bricks é determinada por atributos estendidos armazenados em diretórios, portanto, a distribuição é específica do diretório.
O hash consistente geralmente é pensado como um hash ao redor de um círculo, mas no GlusterFS é mais linear. Não há necessidade de "voltar" a zero, porque sempre há uma quebra (entre o intervalo de uma subunidade e outro) em zero.
Se uma subunidade estiver ausente, haverá uma lacuna no espaço de hash. Ainda pior, se os intervalos de hash forem reatribuídos enquanto uma subunidade estiver offline, alguns dos novos intervalos podem se sobrepor ao intervalo (agora desatualizado) armazenado nessa subunidade, criando um pouco de confusão sobre onde os arquivos devem estar.
Translators AFR - Automatic File Replication
O translator de Replicação Automática de Arquivos (AFR) no GlusterFS utiliza os atributos estendidos para controlar as operações de arquivo. Ele é responsável por replicar os dados entre os bricks. Suas responsabilidades incluem o seguinte:
Manter a consistência da replicação (ou seja, os dados em ambos os bricks devem ser iguais, mesmo nos casos em que há operações ocorrendo no mesmo arquivo/diretório em paralelo a partir de várias aplicações/pontos de montagem, desde que todos os bricks no conjunto de réplicas estejam ativos).
Fornecer uma maneira de recuperar dados em caso de falhas, desde que haja pelo menos um brick que tenha os dados corretos.
Servir dados atualizados para leitura/stat/readdir, etc.
Geo-Replication
A geo-replicação fornece a replicação assíncrona de dados entre locais geograficamente distintos e foi introduzida no GlusterFS 3.2. Ela funciona principalmente através da WAN (Wide Area Network) e é usada para replicar o volume inteiro, ao contrário do AFR, que é uma replicação intra-cluster. Isso é especialmente útil para fazer backup de todos os dados para recuperação de desastres.
A replicação intra-cluster refere-se à replicação de dados que ocorre dentro de um cluster de servidores. Um cluster é um conjunto de computadores interconectados que trabalham juntos como se fossem um único sistema. A replicação intra-cluster, portanto, implica a cópia de dados entre diferentes nós ou servidores dentro desse cluster específico.
A geo-replicação utiliza um modelo Master-Slave, onde a replicação ocorre entre um Master e um Slave, ambos devendo ser volumes GlusterFS. A geo-replicação oferece um serviço de replicação incremental sobre Redes Locais (LANs), Redes de Área Ampla (WANs) e pela Internet.
A replicação assíncrona e a replicação síncrona são abordagens diferentes em relação à sincronização de dados entre sistemas ou locais distintos. Na replicação assíncrona, os dados são copiados de um local para outro de forma não imediata. Isso significa que, quando ocorre uma alteração nos dados no sistema de origem, a replicação para o sistema de destino não é realizada instantaneamente, os dados são replicados em intervalos de tempo predefinidos ou quando determinados critérios são atendidos. Essa abordagem é eficiente em termos de desempenho, pois não impõe a necessidade de esperar pela confirmação da replicação antes de continuar com as operações locais. No entanto, pode haver uma pequena defasagem entre as cópias dos dados no sistema de origem e no sistema de destino.
Na replicação síncrona, cada alteração nos dados no sistema de origem é sincronizada imediatamente com o sistema de destino antes que a operação seja considerada concluída. Isso significa que a gravação no sistema de origem só é confirmada após a replicação bem-sucedida para o sistema de destino. Embora isso garanta consistência entre os sistemas, pode introduzir atrasos nas operações locais, especialmente em ambientes de rede mais lentos. A replicação síncrona pode ser mais suscetível a problemas de desempenho se a latência de rede entre os sistemas for significativa.
Geo-replicação sobre LAN
Você pode configurar a geo-replicação para espelhar dados sobre uma Rede Local (LAN).

Geo-replicação sobre WAN
Você pode configurar a geo-replicação para replicar dados sobre uma Wide Area Network (WAN).

Geo-replicação sobre Internet
Você pode configurar a geo-replicação para espelhar dados pela Internet.

Geo-replicação em cascata em vários locais
Você pode configurar a geo-replicação para espelhar dados de maneira cascata por vários locais.

Existem principalmente dois aspectos ao replicar dados de forma assíncrona:
Change detection
Isso inclui detalhes necessários para operações de arquivo. Existem dois métodos para sincronizar as alterações detectadas:Changelogs
Changelog é um translator que registra detalhes necessários para as operações de arquivo (fops) que ocorrem. As alterações podem ser gravadas em formato binário ou ASCII. Existem três categorias, cada categoria representada por um formato específico de changelog. Todos os três tipos de categorias são registrados em um único arquivo de changelog.- Entrada (Entry): create(), mkdir(), mknod(), symlink(), link(), rename(), unlink(), rmdir()
- Dados (Data): write(), writev(), truncate(), ftruncate()
- Meta (Meta): setattr(), fsetattr(), setxattr(), fsetxattr(), removexattr(), fremovexattr()
- Replication
Utilizamos o rsync para a replicação de dados. O rsync é uma utilidade externa que calcula a diferença entre dois arquivos e envia essa diferença do origem para o destino.
Topologia
Para ao ambiente devemos ter pelo menos dois servidores rodando o GlusterFS, para nosso ambiente teremos então dois servidores rodando o GlusterFS (a documentação oficial recomenda três, mas funciona bem com dois) e uma máquina cliente que será usada para acessar os arquivos que serão disponibilizados pelo Gluster. Tanto os servidores rodando o Gluster quanto a máquina cliente que vai acessar o Gluster é Ubuntu 20.04.5 LTS.
Além disso, cada um dos servidores terão um único disco de 10GB para serem usados no Gluster; Além do disco do Sistema Operacional.

Instalando o GlusterFS
A instalação do GlusterFS vai depender do Sistema Operacional que está em uso, portanto, para fazer a instalação siga o passo a passo oficial. Estou optando pela instalação oficial pelo simples motivo de a versão do GlusterFS disponível no repositório do Ubuntu 20 está com a versão 7.2, enquanto que a versão mais recente é a 7.9.
Após a instalação é preciso habilitar os serviços para subir no boot:
$ sudo systemctl start glusterd.service glusterfssharedstorage.service glustereventsd.service gluster-ta-volume.service
$ sudo systemctl enable glusterd.service glusterfssharedstorage.service glustereventsd.service gluster-ta-volume.service
glusterd.service
Este é o daemon principal do GlusterFS que gerencia a configuração e os serviços do cluster. O glusterd (Gluster Daemon) é responsável por manter a consistência da configuração entre os nós do cluster e gerenciar os volumes do GlusterFS.glusterfssharedstorage.service
Este serviço está associado a volumes compartilhados entre diferentes instâncias do GlusterFS. Ele fornece suporte para compartilhamento de armazenamento entre diferentes hosts no cluster GlusterFS.glustereventsd.service
O glustereventsd (Gluster Events Daemon) é responsável por monitorar eventos e notificações no cluster do GlusterFS. Ele permite a captura e processamento de eventos relacionados a operações no sistema de arquivos distribuído.gluster-ta-volume.service
Este serviço está relacionado a volumes do tipo "Thin Arbiter" no GlusterFS. Volumes do tipo "Thin Arbiter" são usados para otimizar o uso de espaço em clusters distribuídos.
Configurando o ambiente
Em um ambiente com Servidor DNS teríamos que configurar as entradas de DNS para os dois servidores que vão ser o GlusterFS. Mas como nesse ambiente não temos um servidor DNS vamos criar essas entradas no /etc/hosts.
# /etc/hosts para gluster1
127.0.1.1 gluster1
192.168.121.223 gluster1
192.168.121.219 gluster2
192.168.121.6 clientgluster
# /etc/hosts para gluster2
127.0.1.1 gluster2
192.168.121.223 gluster1
192.168.121.219 gluster2
192.168.121.6 clientgluster
# /etc/hosts para clientgluster
127.0.1.1 clientgluster
192.168.121.223 gluster1
192.168.121.219 gluster2
192.168.121.6 clientgluster
Agora vamos configurar o bricks (diretório que será compartilhado) para que possamos criar nosso volume dentro do Gluster:
## Faça no Gluster1 (servidor 1)
# Vamos criar uma nova tabela do tipo GPT no nosso HD:
$ sudo parted /dev/vdb mklabel gpt
# Crie uma partição contendo todo o espaço disponível do disco:
$ echo -e "n\n1\n\n\nt\n\n0FC63DAF-8483-4772-8E79-3D69D8477DE4\nw" | sudo fdisk /dev/vdb
# Agora vamos formatar a partição com o File System EXT4:
$ sudo mkfs.ext4 /dev/vdb1
# Crie um diretório para montarmos o disco:
$ sudo mkdir -p /data/glusterfs
# Agora temos que colocar no FSTAB para montar automaticamente no Boot:
$ echo "$(sudo blkid /dev/vdb1 | awk '{ print $2 }') /data/glusterfs ext4 defaults 1 2" | sudo tee -a /etc/fstab
# Agora monte tudo que está no '/etc/fstab':
$ sudo mount -a
## Faça no Gluster2 (servidor 2)
# Vamos criar uma nova tabela do tipo GPT no nosso HD:
$ sudo parted /dev/vdb mklabel gpt
# Crie uma partição contendo todo o espaço disponível do disco:
$ echo -e "n\n1\n\n\nt\n\n0FC63DAF-8483-4772-8E79-3D69D8477DE4\nw" | sudo fdisk /dev/vdb
# Agora vamos formatar a partição com o File System EXT4:
$ sudo mkfs.ext4 /dev/vdb1
# Crie um diretório para montarmos o disco:
$ sudo mkdir -p /data/glusterfs
# Agora temos que colocar no FSTAB para montar automaticamente no Boot:
$ echo "$(sudo blkid /dev/vdb1 | awk '{ print $2 }') /data/glusterfs ext4 defaults 1 2" | sudo tee -a /etc/fstab
# Agora monte tudo que está no '/etc/fstab':
$ sudo mount -a
Agora vamos corrigir a data/hora do sistema, faça isso em todos os servidores que for usar, é uma boa prática.
- Procedimento no Ubuntu 20.04
- Procedimento no Ubuntu 22.04
# Desabilite o System clock synchronized para uso com NTP:
$ sudo timedatectl set-ntp 0
$ sudo timedatectl set-timezone America/Sao_Paulo
# Agora instale o chrony:
$ sudo apt install chrony -y
# Configure o Chrony para usar servidores Brasileiros (apenas para Ubuntu 20.04):
$ sudo sed -i '/^pool/ s/^/#/' /etc/chrony/chrony.conf && sed -i -e '/^#pool/!b' -e ':a' -e 'N' -e '$!ba' -e 's/^#pool/pool pool.ntp.br iburst maxsources 4\n&/' /etc/chrony/chrony.conf
# Faça o Chrony reler o arquivo de configuração (Ubuntu 20.04):
$ sudo systemctl restart chrony
# Desabilite o System clock synchronized para uso com NTP:
$ sudo timedatectl set-ntp 0
$ sudo timedatectl set-timezone America/Sao_Paulo
# Agora instale o chrony:
$ sudo apt install chrony -y
# Configure o Chrony para usar servidores Brasileiros (apenas para Ubuntu 22.04):
$ sudo sed -ri '/^pool/d' /etc/chrony/chrony.conf
$ sudo bash -c 'echo pool pool.ntp.br iburst maxsources 4 > /etc/chrony/sources.d/ntp.sources'
# Faça o Chrony reler o arquivo de configuração (Ubuntu 22.04):
$ sudo chronyc reload sources
Configurando o Trusted Pool
Vamos criar nosso Cluster, para que então os servidores dentro do Cluster possam trocar dados entre sí.
## No gluster1
$ sudo gluster peer probe gluster2
peer probe: success.
## No gluster2 não é preciso refazer o comando, pois já foi criado o cluster e nele estão inclusos o gluster1 e gluster2, mas se quiser rodar...
$ sudo gluster peer probe gluster1
peer probe: success. Host gluster1 port 24007 already in peer list
# Podemos verificar o status do Cluster, olhando no Gluster1:
root@gluster1:~$ gluster peer status
Number of Peers: 1
Hostname: gluster2
Uuid: 8a6b7b08-cb65-4b1e-9a99-311e72b34ef9
State: Peer in Cluster (Connected)
# Podemos verificar o status do Cluster, olhando no Gluster2:
root@gluster2:~$ gluster peer status
Number of Peers: 1
Hostname: gluster1
Uuid: a5aed138-adfa-4073-8100-54da83d80923
State: Peer in Cluster (Connected)
Configurando um volume
O tipo de volume Gluster mais básico é um volume Somente distribuição, se não for especificado qual o tipo de volume, esse tipo será criado. Os volumes são criados para agregar os Bricks, para que assim outras máquinas possam acessar os volumes gerenciados pelo Gluster. Para relembrar os tipos de volumes acesse aqui.
Configurando um volume distribuído
Vamos começar configurando um volume distribuído com apenas um servidor, para então adicionar outro futuramente, apenas para vermos como seria ter que adicionar um novo servidor (bricks nesse caso) ao volume.
## Sintaxe: gluster volume create <volume_name> <node_name>:<path_to_brick>
# Criando o volume no Gluster1:
$ sudo gluster volume create vol1 gluster1:/data/glusterfs/brick
volume create: vol1: success: please start the volume to access data
# No caso de '/data/glusterfs/brick' é o diretório que será usado pelo Gluster.
# Veja informações do volume:
$ sudo gluster volume info
Volume Name: vol1
Type: Distribute
Volume ID: 8a69212f-89c7-4786-abfe-6622d15f8ac5
Status: Created
Snapshot Count: 0
Number of Bricks: 1
Transport-type: tcp
Bricks:
Brick1: gluster1:/data/glusterfs/brick
Options Reconfigured:
transport.address-family: inet
storage.fips-mode-rchecksum: on
nfs.disable: on
# Após criar o volume, inicie-o:
$ sudo gluster volume start vol1
volume start: vol1: success
# Podemos ver o status de todos os volumes ativos:
$ sudo gluster vol status
Status of volume: vol1
Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick gluster1:/data/glusterfs/brick 49152 0 Y 5944
Task Status of Volume vol1
------------------------------------------------------------------------------
There are no active volume tasks
Caso tenha mais de uma interface no servidor e queira forçar o GlusterD a escutar apenas numa única interface, faça:
$ sudo vim /etc/glusterfs/glusterd.vol
## Adicione:
option transport.tcp.bind-address 192.168.121.140
option transport.rdma.bind-address 192.168.121.140
option transport.socket.bind-address 192.168.121.140
# Faça um restart manual nos volumes ativos para fazer com que a configuração nova entre em vigor:
$ sudo gluster vol stop vol1
$ sudo systemctl restart glusterd
$ sudo gluster vol start vol1
transport.rdma.bind-address:- RDMA (Remote Direct Memory Access) é uma tecnologia que permite que os servidores acessem diretamente a memória uns dos outros sem a intervenção da CPU.
- Esta opção define o endereço IP ao qual o RDMA será vinculado.
transport.socket.bind-address:- Este se refere ao transporte padrão do GlusterFS que usa soquetes (sockets) para a comunicação entre os nós do cluster.
- Define o endereço IP ao qual os sockets serão vinculados.
transport.tcp.bind-address:- Semelhante à opção de soquete, esta refere-se ao transporte TCP usado pelo GlusterFS.
- Define o endereço IP ao qual as conexões TCP serão vinculadas.
Cliente GlusterFS com GNC - Gluster Native Client
Vamos instalar o pacote do GlusterFS para usar o Gluster Native Client:
# Instale o GluserFS no Cliente:
sudo apt -y install glusterfs-client
Agora para montar o volume, podemos usar:
# Montar manualmente:
sudo mount -t glusterfs gluster1:/vol1 /mnt
# Para montar no boot:
sudo vim /etc/fstab
## Adicione a linha:
gluster1:/vol1 /mnt glusterfs defaults,_netdev 0 0
Ao usar o comando mount -t glusterfs, podemos fornecer algumas opções separadas por vírgulas para personalizar o comportamento da montagem do sistema de arquivos Gluster.
| Opção | Descrição |
|---|---|
| backupvolfile-server | Especifica o servidor a partir do qual o arquivo volfile (arquivo de definição do volume) deve ser copiado se não estiver disponível localmente. |
| volfile-max-fetch-attempts | Especifica o número máximo de tentativas para buscar o arquivo volfile antes de falhar ao montar o volume. |
| log-level | Define o nível de detalhe do log para mensagens do GlusterFS, ajudando no diagnóstico de problemas. Os níveis são: EMERG, ALERT, CRIT, ERR, WARNING, NOTICE, INFO, DEBUG e TRACE. |
| log-file | Especifica o caminho do arquivo de log onde as mensagens do GlusterFS serão registradas. |
| transport | Define o tipo de transporte a ser usado para comunicação entre os clientes e servidores GlusterFS. Pode ser tcp, rdma. |
| direct-io-mode | Ativa (enable) ou desativa (disable) o modo de E/S direta. Quando ativado, as operações de E/S são realizadas diretamente sem buffer. |
| use-readdirp | Especifica se o readdirp (operação de leitura de diretório com atributos) deve ser habilitado (yes) ou desabilitado (no). |
Adicionando brick para um volume
Agora vamos colocar o gluster2 (segundo node dentro do trusted pool) para que tenhamos dois bricks dentro do volume já criado (no nosso caso é o vol1), como nosso volume é distribuído isso resultará num aumento do armazenamento, ou seja, se tivermos dois bricks cada um com 10GB, quando o cliente mapear isso, ele irá ver um armazenamento total com 20GB. Note que por ser um volume distribuído não teremos redundância dos dados.
Para fazer isso temos que acessar o servidor onde o volume já exista, no caso a partir do gluster1 que é onde o volume vol1 já existe, temos que adicionar o segundo brick ao trusted pool. Como os dois servidores já estão no trusted pool não precisaremos adicionar nenhum outro servidor, mas caso tivessemos apenas um único servidor, teríamos que adicionar ele ao cluster (trusted pool) para então adicionar o brick.
# Antes de começarmos, vejamos o tamanho do armazenamento do Gluster que é reconhecido pelo cliente:
$ df -h /mnt
Filesystem Size Used Avail Use% Mounted on
gluster1:/vol1 9.8G 100M 9.3G 2% /mnt
# A partir do gluster1 adicione o brick do gluster2 ao vol1:
root@gluster1:~# sudo gluster volume add-brick vol1 gluster2:/data/glusterfs/brick
volume add-brick: success
# Agora podemos exibir informações do volume:
$ sudo gluster vol info vol1
Volume Name: vol1
Type: Distribute
Volume ID: 8a69212f-89c7-4786-abfe-6622d15f8ac5
Status: Started
Snapshot Count: 0
Number of Bricks: 2
Transport-type: tcp
Bricks:
Brick1: gluster1:/data/glusterfs/brick
Brick2: gluster2:/data/glusterfs/brick
Options Reconfigured:
transport.address-family: inet
storage.fips-mode-rchecksum: on
nfs.disable: on
# Vejamos novamente o tamanho do armazenamento do Gluster que é reconhecido pelo cliente:
$ df -h /mnt
Filesystem Size Used Avail Use% Mounted on
gluster1:/vol1 20G 200M 19G 2% /mnt
Não precisa fazer nada no cliente, essa mudança será transparente.
Removendo brick para um volume
Como teste vamos remover um brick, só temos que tomar cuidado, já que nosso volume é distribuído podemos perder alguns dados, portanto, temos que copiar manualmente os dados que estiverem num disco para outro. É possível remover volumes conforme necessário enquanto o cluster estiver online e disponível. Por exemplo, pode ser necessário remover um bloco que se tornou inacessível em um volume distribuído devido a falha de hardware ou de rede.
Os dados que residem no bloco que você está removendo não serão mais acessíveis no ponto de montagem do Gluster. No entanto, observe que apenas as informações de configuração são removidas; você ainda pode acessar os dados diretamente do bloco, conforme necessário.
Ao remover volumes distribuídos replicados e volumes distribuídos dispersos, é necessário remover um número de blocos que seja um múltiplo do número de réplicas ou do número de listras. Por exemplo, para encolher um volume distribuído replicado com um número de réplicas igual a 2, é necessário remover blocos em múltiplos de 2 (como 4, 6, 8, etc.). Além disso, os blocos que você está tentando remover devem ser da mesma subunidade, ou seja, remover às cópias dos dados que estão armazenadas em diferentes nodes do cluster. Por exemplo, se você tem um volume distribuído replicado com uma configuração de réplica igual a 2, significa que há duas cópias de cada bloco de dados, armazenadas em diferentes nodes para fins de redundância. Ao remover dados, você precisa garantir que está removendo blocos de ambas as cópias para manter a consistência.
# Antes de começarmos, vejamos o tamanho do armazenamento do Gluster que é reconhecido pelo cliente:
$ df -h /mnt
Filesystem Size Used Avail Use% Mounted on
gluster1:/vol1 20G 200M 19G 2% /mnt
# Desative 'cluster.force-migration':
$ sudo gluster volume set vol1 cluster.force-migration disable
volume set: success
# No Gluster2, "Desative" o brick:
$ sudo gluster volume remove-brick vol1 gluster1:/data/glusterfs/brick start
It is recommended that remove-brick be run with cluster.force-migration option disabled to prevent possible data corruption. Doing so will ensure that files that receive writes during migration will not be migrated and will need to be manually copied after the remove-brick commit operation. Please check the value of the option and update accordingly.
Do you want to continue with your current cluster.force-migration settings? (y/n) y
volume remove-brick start: success
ID: b9f100d3-8065-41dd-97bb-8ef68c6afbd0
# Verifique se o status de remoção está como 'completed':
$ sudo gluster volume remove-brick vol1 gluster1:/data/glusterfs/brick status
Node Rebalanced-files size scanned failures skipped status run time in h:m:s
--------- ----------- ----------- ----------- ----------- ----------- ------------ --------------
gluster1 0 0Bytes 0 0 0 completed 0:00:00
# Verifique o status dos volumes e veja que tem as tarefas que mandados executar de remover:
$ sudo gluster vol status
Status of volume: vol1
Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick gluster1:/data/glusterfs/brick 49152 0 Y 5731
Brick gluster2:/data/glusterfs/brick 49152 0 Y 5727
Task Status of Volume vol1
------------------------------------------------------------------------------
Task : Remove brick
ID : b9f100d3-8065-41dd-97bb-8ef68c6afbd0
Removed bricks:
gluster1:/data/glusterfs/brick
Status : completed
# Após ficar 'completed' podemos aplicar a remoção:
$ sudo gluster volume remove-brick vol1 gluster1:/data/glusterfs/brick commit
volume remove-brick commit: success
Check the removed bricks to ensure all files are migrated.
If files with data are found on the brick path, copy them via a gluster mount point before re-purposing the removed brick.
# Vejamos novamente o tamanho do armazenamento do Gluster que é reconhecido pelo cliente:
$ df -h /mnt
Filesystem Size Used Avail Use% Mounted on
gluster1:/vol1 9.8G 100M 9.3G 2% /mnt
# Verifique novamente o status:
$ sudo gluster vol status
Status of volume: vol1
Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick gluster2:/data/glusterfs/brick 49152 0 Y 5727
Task Status of Volume vol1
------------------------------------------------------------------------------
There are no active volume tasks
Configurando um volume replicado
Vamos começar configurando um volume replicado com apenas um servidor, para então adicionar outro futuramente, apenas para vermos como seria ter que adicionar um novo servidor (bricks nesse caso) ao volume.
## Sintaxe: gluster volume create <volume_name> replica 2 <node_name>:<path_to_brick>
# Criando o volume no Gluster1:
$ sudo gluster volume create vol1 replica 2 gluster1:/data/glusterfs/brick
volume create: vol1: success: please start the volume to access data
# A opção 'replica 2' é porque vamos usar dois bricks, um em cada servidor.
# Veja informações do volume:
$ sudo gluster volume info
Volume Name: vol1
Type: Distribute
Volume ID: 8a69212f-89c7-4786-abfe-6622d15f8ac5
Status: Created
Snapshot Count: 0
Number of Bricks: 1
Transport-type: tcp
Bricks:
Brick1: gluster1:/data/glusterfs/brick
Options Reconfigured:
transport.address-family: inet
storage.fips-mode-rchecksum: on
nfs.disable: on
O número de bricks deve ser igual à contagem de réplicas de um volume replicado, ou seja, 3 servidores é igual a 3 bricks. Para proteção contra falhas de servidor e disco, é recomendado que os blocos do volume sejam de servidores diferentes.
Aqui usamos replica 2 porque temos dois servidores, se tivessemos três, seria replica 3, se fossem quatro, seria replica 4. Isso é diferente de quando estamos trabalhando com volumes Distributed Replicated (Distribuído Replicado).
Cliente GlusterFS com GNC - Gluster Native Client
Vamos instalar o pacote do GlusterFS para usar o Gluster Native Client:
# Instale o GluserFS no Cliente:
sudo apt -y install glusterfs-client
Agora para montar o volume, podemos usar:
# Montar manualmente:
sudo mount -t glusterfs gluster1:/vol1 /mnt
# Para montar no boot:
sudo vim /etc/fstab
## Adicione a linha:
gluster1:/vol1 /mnt glusterfs defaults,_netdev 0 0
Ao usar o comando mount -t glusterfs, podemos fornecer algumas opções separadas por vírgulas para personalizar o comportamento da montagem do sistema de arquivos Gluster.
| Opção | Descrição |
|---|---|
| backupvolfile-server | Especifica o servidor a partir do qual o arquivo volfile (arquivo de definição do volume) deve ser copiado se não estiver disponível localmente. |
| volfile-max-fetch-attempts | Especifica o número máximo de tentativas para buscar o arquivo volfile antes de falhar ao montar o volume. |
| log-level | Define o nível de detalhe do log para mensagens do GlusterFS, ajudando no diagnóstico de problemas. Os níveis são: EMERG, ALERT, CRIT, ERR, WARNING, NOTICE, INFO, DEBUG e TRACE. |
| log-file | Especifica o caminho do arquivo de log onde as mensagens do GlusterFS serão registradas. |
| transport | Define o tipo de transporte a ser usado para comunicação entre os clientes e servidores GlusterFS. Pode ser tcp, rdma. |
| direct-io-mode | Ativa (enable) ou desativa (disable) o modo de E/S direta. Quando ativado, as operações de E/S são realizadas diretamente sem buffer. |
| use-readdirp | Especifica se o readdirp (operação de leitura de diretório com atributos) deve ser habilitado (yes) ou desabilitado (no). |
Adicionando brick para um volume (inativo)
Agora vamos colocar o gluster2 (segundo node dentro do trusted pool) para que tenhamos dois bricks dentro do volume já criado (no nosso caso é o vol1), como nosso volume é replicado isso resultará numa duplicação dos dados, lembre-se que o mínimo de bricks é 2. Note que por ser um volume replicado nós teremos redundância dos dados.
Para fazer isso temos que acessar o servidor onde o volume já exista, no caso a partir do gluster1 que é onde o volume vol1 já existe, temos que adicionar o segundo brick ao trusted pool. Como os dois servidores já estão no trusted pool não precisaremos adicionar nenhum outro servidor, mas caso tivessemos apenas um único servidor, teríamos que adicionar ele ao cluster (trusted pool) para então adicionar o brick.
# Criando o volume no Gluster1:
$ sudo gluster volume create vol1 replica 3 gluster1:/data/glusterfs/brick gluster2:/data/glusterfs/brick gluster3:/data/glusterfs/brick
# Veja informações do volume:
$ sudo gluster volume info
# Após criar o volume, inicie-o:
$ sudo gluster volume start vol1
# Podemos ver o status de todos os volumes ativos:
$ sudo gluster vol status
Removendo brick para um volume (inativo)
Como teste vamos remover um brick, só temos que tomar cuidado, em um volume replicado com dois servidores ficaremos sem redundância ao remover um único brick. Ao remover volumes distribuídos replicados e volumes distribuídos dispersos, é necessário remover um número de blocos que seja um múltiplo do número de réplicas ou do número de listras. Por exemplo, para encolher um volume distribuído replicado com um número de réplicas igual a 2, é necessário remover blocos em múltiplos de 2 (como 4, 6, 8, etc.).
Além disso, os blocos que você está tentando remover devem ser da mesma subunidade, ou seja, remover às cópias dos dados que estão armazenadas em diferentes nodes do cluster. Por exemplo, se você tem um volume distribuído replicado com uma configuração de réplica igual a 2, significa que há duas cópias de cada bloco de dados, armazenadas em diferentes nodes para fins de redundância. Ao remover dados, você precisa garantir que está removendo blocos de ambas as cópias para manter a consistência.
GlusterFS no Cliente (inativo)
Vamos ver como montar o Gluster na máquina cliente usando diferentes métodos.
Cliente GlusterFS com NFS v3 (inativo)
Vamos montar o volume do Gluster via NFS:
# Primeiro instale o cliente do NFS:
sudo aptitude install nfs-common
# Agora vamos montar, o Gluster roda apenas em NFS v3 (não funciona com NFS v4):
sudo mount -t nfs -o proto=tcp,vers=3 gluster1:/vol1 /mnt
# Para montar no Boot:
sudo vim /etc/fstab
## Adicione a linha:
gluster1:/vol1 /mnt nfs defaults,_netdev,proto=tcp,vers=3 0 0
GlusterFS com Samba
Para usar o GlusterFS com o Samba, vamos usar um módulo nativo do Samba chamado vfs_glusterfs. Esse módulo trabalha muito melhor já que é um módulo integrada ao Samba, operando de forma diferente ao que está documentado na documentação oficial do GlusterFS.
A maneira como está descrito na documentação oficial do GlusterFS é apontando um share na configuração do Samba para o diretório onde o GlusterFS está montado. Dessa forma, acaba usando o FUSE que é mais lento e menos confiável se comparado com o módulo do nativo.
Com o samba já instalado e configrado, vamos instalar o pacote necessário para integrar o Samba ao GlusterFS`:
# Instale o pacote abaixo:
$ sudo apt install -y samba-vfs-modules
# Após instalado, os módulos vão ficar no caminho abaixo:
## /usr/lib/x86_64-linux-gnu/samba/vfs/
O pacote mais importante no caminho informado é o /usr/lib/x86_64-linux-gnu/samba/vfs/glusterfs_fuse.so, antes de continuar, verifique se este arquivo existe!
Agora vamos adicionar a configuração do Samba para acessar o GlusterFS diretamente.
# Edite o arquivo abaixo:
$ sudo vim /etc/samba/smb.conf
### Adicione as linhas abaixo ###
[docsgv01]
vfs objects = glusterfs
path = /
glusterfs:volume = vol1
kernel share modes = no
guest ok = yes
writable = yes
### Fim das linhas acima ###
# Agora rode um teste no Samba para verificar algum erro de sintaxe:
$ sudo testparm
# Agora reinicie o Samba:
$ sudo systemctl restart smbd
Lembrando que essa configuração do Samba é apenas para exemplificar como seria, não se deve usar algo semelhante em um ambiente de produção sem ter certeza do que está fazendo.
Comandos
| Comando | Descrição |
|---|---|
| gluster peer status | Exibe o status do Cluster e quem são os nodes participantes. |
| gluster peer probe server_name | Adiciona o servidor ao Cluster, pode usar o IP ou o nome (será feito resolução de DNS). |
| gluster peer detach server_name | Remove o servidor do Cluster, pode usar o IP ou o nome (será feito resolução de DNS). |
| gluster pool list | Lista todos os servidores que pertencem ao Cluster. |
| gluster volume info | Exibe os volumes (se existentes) no servidor em que o comando foi executado. |
| gluster volume status | Exibe o status de todos os Volumes ativos. |
| gluster volume stop volume_name | Para o volume indicado, desativando o uso do mesmo. |
| gluster volume start volume_name | Inicia o volume indicado, ativando o uso do mesmo. |
| gluster volume delete volume_name | Deleta o volume, mas antes é necessário parar o volume. Remover um volume não apaga os dados nele. |
| gluster volume set volume_name options value | Configura opções (options) para o volume informado, o parâmetro que vamos configurar deve ser fornecido em value. |
| gluster volume get volume_name all | Exibe todos as opções para o Volume, podemos especificar por volume também. |
| gluster volume create volume_name server_name:brick_path | Cria um volume com o brick para o servidor indicado. |
| gluster volume add-brick volume_name server_name:brick_path | Adiciona um novo brick dentro de um volume já criado. |
| gluster volume remove-brick volume_name server_name:brick_path start | Começa o processo de remoção de um brick do volume, é como se o volume estivesse sendo desativado. Para maior segurança recomenda-se que seja executado com a opção cluster.force-migration desabilitada para evitar possível corrupção de dados. Isso garantirá que os arquivos que recebem gravações durante a migração não serão migrados e precisarão ser copiados manualmente após a operação de commit remove-brick. |
| gluster volume remove-brick volume_name server_name:brick_path status | Mostra o status da remoção do Brick, após a remoção completa é necessário dar um commit. |
| gluster volume remove-brick volume_name server_name:brick_path commit | Após o status complete no comando acima, devemos remover de vez o Brick, depois desse passo o brick não será mais listado no volume. |
| gluster volume heal volume_name info | Visualizar a lista de arquivos que precisam de cura. |
| gluster volume heal volume_name | Acionar a self-heal apenas nos arquivos que precisam de cura. |
| gluster volume heal volume_name full | Acionar a self-heal em todos os arquivos de um volume. |
| gluster volume heal volume_name info healed | Veja a lista de arquivos que são auto-reparáveis em um volume específico. |
| gluster volume heal volume_name info failed | Veja a lista de arquivos de um volume específico nos quais a autocorreção falhou. |
| gluster volume heal volume_name info split-brain | Veja a lista de arquivos de um volume específico que estão em estado de cérebro dividido. |
| gluster volume rebalance volume_name fix-layout start | Corrige as informações de layout para que os arquivos possam ser criados nos blocos recém-adicionados, em outras palavras, inicia o rebalanceamento após a execução do comando, o que já existir ficará "desbalanceado". |
| gluster volume rebalance volume_name start | Faz o mesmo que o comando acima, porém, migra os dados existentes para reequilibrar os dados entre os servidores. |
| gluster volume rebalance volume_name status | Exibe o status da operação de reequilíbrio. |
| gluster volume rebalance volume_name stop | Para a operação de reequilíbrio. |
Fontes
https://docs.gluster.org/en/latest/
https://docs.gluster.org/en/latest/Quick-Start-Guide/Architecture/
https://docs.gluster.org/en/latest/Quick-Start-Guide/Quickstart/#advantages
https://serverfault.com/questions/796036/should-i-mount-glusterfs-as-nfs-or-fuse
https://docs.gluster.org/en/main/Administrator-Guide/Managing-Volumes/