Introdução ao ECMP
O ECMP (Equal-Cost Multi-Path) é uma técnica usada em roteadores para distribuir tráfego entre múltiplos caminhos que possuem o mesmo custo até um destino. Em vez de escolher apenas um caminho como fazem os algoritmos tradicionais de roteamento, o ECMP permite o uso de vários caminhos em paralelo, otimizando o uso de banda e aumentando a resiliência da rede.
Quando um roteador aprende múltiplas rotas para um mesmo destino com o mesmo custo administrativo e métrica, ele pode:
- Armazenar todas essas rotas na tabela de encaminhamento (FIB).
- Usar um algoritmo de hash (ex: baseado no IP de origem/destino, porta, protocolo) para escolher por qual caminho enviar cada fluxo.
- Balancear o tráfego de forma determinística, mantendo cada fluxo no mesmo caminho para evitar reordenação de pacotes.
A maioria dos protocolos de Roteamento suportam ECMP, alguns são mais fáceis de configurar do que outros.
- OSPF: Permite múltimos caminhos com o mesmo cost.
- IS-IS: Também suporta múltiplos caminhos com o mesmo metric.
- BGP: Suporta ECMP, mas precisa ser explicitamente configurado (e depende de atributos como AS_PATH, MED, etc. serem idênticos).
- EIGRP: Suporta ECMP e inclusive unequal-cost multipath, com pesos diferentes.
Funcionamento do ECMP
Imagina um roteador chamado R1 que precisa encaminhar pacotes para a rede 192.0.2.0/24. Esse roteador está conectado a dois outros roteadores, R2 e R3, e ambos anunciam essa mesma rede (192.0.2.0/24) via OSPF com o mesmo custo. Ou seja, tanto o caminho via R2 quanto o caminho via R3 têm o mesmo valor de métrica na visão do R1.
Quando o R1 recebe essas rotas por OSPF, o protocolo percebe que os dois caminhos têm exatamente o mesmo custo. Em vez de escolher apenas um deles e descartar o outro, como seria feito normalmente num roteamento sem ECMP, o R1 mantém as duas rotas na tabela de encaminhamento. Isso só acontece porque o protocolo e o sistema operacional suportam ECMP (Equal-Cost Multi-Path).
Agora, quando o R1 recebe um pacote destinado a algum IP dentro da rede 192.0.2.0/24, ele precisa decidir por qual desses dois caminhos (R2 ou R3) o pacote será enviado. Para isso, ele usa uma função de hash, geralmente baseada em informações dos pacotes (como IP de origem, IP de destino, protocolo, portas de origem e destino) para garantir que cada fluxo de conexão siga sempre o mesmo caminho. Assim, se um cliente começa a se comunicar com um servidor, todos os pacotes dessa conversa seguem pela mesma rota, evitando que cheguem fora de ordem no destino.
Por exemplo, se você estiver assistindo um vídeo de um servidor naquela rede, o primeiro pacote do seu fluxo pode ser encaminhado via R2. A função de hash grava essa escolha, e os próximos pacotes do mesmo fluxo continuarão passando por R2. Já um outro fluxo, como a atualização de software de outro dispositivo na sua rede, pode acabar indo por R3. Isso garante que os dois links estão sendo utilizados ao mesmo tempo, aproveitando a capacidade total disponível.
Se, por acaso, o link entre R1 e R2 falhar, o roteador imediatamente remove essa rota da tabela e passa a enviar tudo por R3, isso acontece de forma automática, sem precisar de intervenção, e os fluxos novos passam a seguir pela rota ainda disponível.
Essa é a base do ECMP funcionando na prática, você tem dois caminhos de igual custo até um destino, e em vez de escolher um só, o roteador usa os dois simultaneamente, mantendo cada fluxo por um caminho consistente. Isso melhora o desempenho, dá redundância e evita que um link fique ocioso enquanto o outro é sobrecarregado.
ECMP na Prática
Vamos ver como trabalhar com ECMP no OSPF para fazer um balanceamento de carga. Vamos fazer vários servidores responderem pelo mesmo serviço usando apenas roteamento. O OSPF detecta todos os caminhos com o mesmo custo e o roteador distribui os fluxos entre eles via ECMP (Equal‑Cost Multi‑Path).
Vamos usar o cenário abaixo:
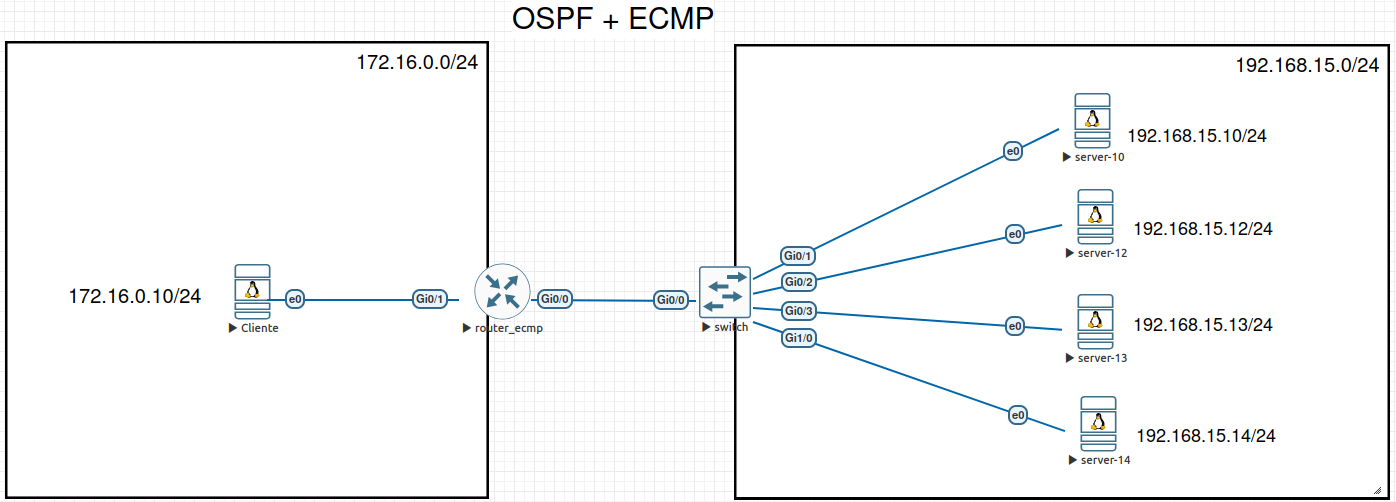
Cada servidor receberá:
Um IP exclusivo, usado para gestão e identificação individual;
Um IP idêntico em todos os nós, configurado na dummy0, que servirá como VIP.
Ao anunciar esse VIP via OSPF, o roteador verá vários caminhos de custo igual e dividirá o tráfego entre os servidores, garantindo alta disponibilidade e balanceamento.
A VIP é um endereço IP "virtual", não amarrado a um hardware único. Fica ativo em vários nós (ou pode "flutuar" entre eles) para oferecer alta disponibilidade e balanceamento de carga. Os clientes enxergam um único endereço, por trás dele há vários servidores respondendo. Pode ser anunciado por roteamento (anycast/ECMP) ou via protocolos de fail‑over (VRRP/Keepalived).
Vamos usar o seguinte endereçamento para o LAB:
| Função | Endereço | Comentário |
|---|---|---|
| Roteador | 192.168.15.1/24 | Gateway da LAN. |
| Servers | 192.168.15.0/24 | /32 locais (e /24 na interface física) para gestão e OSPF. |
| VIP (dummy0) | 192.168.20.10/32 | Anunciado por todos os servidores; roteado, nunca respondido por ARP. |
Vou começar instalando o o BIRD nos servidores, esse mesmo procedimento vale para todos os servidores. Como estou trabalhando com EVE-NG, alguns comandos extras são necessários:
# Configura a velocidade da interface no Linux, desativa a autonegociação e
# configura a interface para Full duplex:
ethtool -s eth0 autoneg off speed 1000 duplex full
# Baixe a chave do repositório do BIRD:
wget -O /usr/share/keyrings/cznic-labs-pkg.gpg https://pkg.labs.nic.cz/gpg
# Configure o repo do BIRD:
echo "deb [signed-by=/usr/share/keyrings/cznic-labs-pkg.gpg] https://pkg.labs.nic.cz/bird3 jammy main" | sudo tee /etc/apt/sources.list.d/cznic-labs-bird3.list
# Atualize o indice de pacotes:
apt-get update
# Instale os pacotes necessários:
apt-get -y install apt-transport-https ca-certificates wget bird3
Configurando os Servers
#####################
# #
# ROUTER 10 #
# #
#####################
hostnamectl set-hostname server_10
cat << 'EOF' > /etc/netplan/01-cluster.yaml
network:
version: 2
ethernets:
eth0:
dhcp4: false
dhcp6: false
accept-ra: false
addresses:
- 192.168.15.10/24
routes:
- to: 0.0.0.0/0
via: 192.168.15.1
on-link: true
dummy0:
addresses:
- 192.168.20.10/32
EOF
# Vamos informar ao 'systemd-networkd' que existe uma interface chamada "dummy0":
cat << 'EOF' > /etc/systemd/network/dummy1.netdev
[NetDev]
Name=dummy0
Kind=dummy
EOF
# Aplique as configurações do Netplan:
netplan apply
# Reinicie o networkd:
systemctl restart systemd-networkd
# Verifique o status da Dummy0:
networkctl status dummy0
● 4: dummy0
Link File: /usr/lib/systemd/network/99-default.link
Network File: /run/systemd/network/10-netplan-dummy0.network
Type: ether
State: routable (configured)
Online state: online
Driver: dummy
HW Address: 7a:20:72:51:c1:f8
MTU: 1500
QDisc: noqueue
IPv6 Address Generation Mode: eui64
Queue Length (Tx/Rx): 1/1
Address: 192.168.20.10
fe80::7820:72ff:fe51:c1f8
Activation Policy: up
Required For Online: yes
DHCP6 Client DUID: DUID-EN/Vendor:0000ab116cb05daee96bb7a70000
Jul 25 21:11:48 ubuntu systemd-networkd[1074]: dummy0: netdev ready
Jul 25 21:11:48 ubuntu systemd-networkd[1074]: dummy0: Link UP
Jul 25 21:11:48 ubuntu systemd-networkd[1074]: dummy0: Gained carrier
Jul 25 21:11:48 ubuntu systemd-networkd[1074]: dummy0: Gained IPv6LL
ip -br addr show dummy0
dummy0 UNKNOWN 192.168.20.10/32 fe80::7820:72ff:fe51:c1f8/64
# Configure o BIRD:
cat << 'EOF' > /etc/bird/bird.conf
router id 192.168.15.10;
protocol direct {
ipv4;
ipv6;
interface "dummy*";
}
protocol device {
scan time 10;
}
function is_invalid_net() -> bool {
return net ~ [
192.168.20.10/32,
192.168.15.0/24,
0.0.0.0/0
];
}
filter kernel_out {
if is_invalid_net() then reject;
else accept;
}
protocol kernel {
ipv4 {
export filter kernel_out;
import none;
};
# importa rotas de volta ao BIRD:
learn;
scan time 20;
}
filter export_vip {
if net = 192.168.20.10/32 then accept;
reject;
}
protocol ospf v2 CLUSTER {
ipv4 {
import all;
export filter export_vip;
};
area 0.0.0.0 {
interface "eth0" {
type broadcast;
};
};
}
EOF
# Habilitar o Root no SSH para testar o load balance:
sed -i 's/#PermitRootLogin.*/PermitRootLogin yes/g' /etc/ssh/sshd_config
systemctl restart sshd ssh
# Reinicie o Bird:
systemctl restart bird
# Verifique os vizinhos OSPF:
birdc show ospf neighbors
#####################
# #
# ROUTER 12 #
# #
#####################
hostnamectl set-hostname server_12
cat << 'EOF' > /etc/netplan/01-cluster.yaml
network:
version: 2
ethernets:
eth0:
dhcp4: false
dhcp6: false
accept-ra: false
addresses:
- 192.168.15.12/24
routes:
- to: 0.0.0.0/0
via: 192.168.15.1
on-link: true
dummy0:
addresses:
- 192.168.20.10/32
EOF
# Vamos informar ao 'systemd-networkd' que existe uma interface chamada "dummy0":
cat << 'EOF' > /etc/systemd/network/dummy1.netdev
[NetDev]
Name=dummy0
Kind=dummy
EOF
# Aplique as configurações do Netplan:
netplan apply
# Reinicie o networkd:
systemctl restart systemd-networkd
# Verifique o status da Dummy0:
networkctl status dummy0
● 4: dummy0
Link File: /usr/lib/systemd/network/99-default.link
Network File: /run/systemd/network/10-netplan-dummy0.network
Type: ether
State: routable (configured)
Online state: online
Driver: dummy
HW Address: 7a:20:72:51:c1:f8
MTU: 1500
QDisc: noqueue
IPv6 Address Generation Mode: eui64
Queue Length (Tx/Rx): 1/1
Address: 192.168.20.10
fe80::7820:72ff:fe51:c1f8
Activation Policy: up
Required For Online: yes
DHCP6 Client DUID: DUID-EN/Vendor:0000ab116cb05daee96bb7a70000
Jul 25 21:11:48 ubuntu systemd-networkd[1074]: dummy0: netdev ready
Jul 25 21:11:48 ubuntu systemd-networkd[1074]: dummy0: Link UP
Jul 25 21:11:48 ubuntu systemd-networkd[1074]: dummy0: Gained carrier
Jul 25 21:11:48 ubuntu systemd-networkd[1074]: dummy0: Gained IPv6LL
# Configure o BIRD:
cat << 'EOF' > /etc/bird/bird.conf
router id 192.168.15.12;
protocol direct {
ipv4;
ipv6;
interface "dummy*";
}
protocol device {
scan time 10;
}
function is_invalid_net() -> bool {
return net ~ [
192.168.20.10/32,
192.168.15.0/24,
0.0.0.0/0
];
}
filter kernel_out {
if is_invalid_net() then reject;
else accept;
}
protocol kernel {
ipv4 {
export filter kernel_out;
import none;
};
# importa rotas de volta ao BIRD:
learn;
scan time 20;
}
filter export_vip {
if net = 192.168.20.10/32 then accept;
reject;
}
protocol ospf v2 CLUSTER {
ipv4 {
import all;
export filter export_vip;
};
area 0.0.0.0 {
interface "eth0" {
type broadcast;
};
};
}
EOF
# Habilitar o Root no SSH para testar o load balance:
sed -i 's/#PermitRootLogin.*/PermitRootLogin yes/g' /etc/ssh/sshd_config
systemctl restart sshd ssh
# Reinicie o Bird:
systemctl restart bird
# Verifique os vizinhos OSPF:
birdc show ospf neighbors
#####################
# #
# ROUTER 10 #
# #
#####################
hostnamectl set-hostname server_10
cat << 'EOF' > /etc/netplan/01-cluster.yaml
network:
version: 2
ethernets:
eth0:
dhcp4: false
dhcp6: false
accept-ra: false
addresses:
- 192.168.15.10/24
routes:
- to: 0.0.0.0/0
via: 192.168.15.1
on-link: true
dummy0:
addresses:
- 192.168.20.10/32
EOF
# Vamos informar ao 'systemd-networkd' que existe uma interface chamada "dummy0":
cat << 'EOF' > /etc/systemd/network/dummy1.netdev
[NetDev]
Name=dummy0
Kind=dummy
EOF
# Aplique as configurações do Netplan:
netplan apply
# Reinicie o networkd:
systemctl restart systemd-networkd
# Verifique o status da Dummy0:
networkctl status dummy0
● 4: dummy0
Link File: /usr/lib/systemd/network/99-default.link
Network File: /run/systemd/network/10-netplan-dummy0.network
Type: ether
State: routable (configured)
Online state: online
Driver: dummy
HW Address: 7a:20:72:51:c1:f8
MTU: 1500
QDisc: noqueue
IPv6 Address Generation Mode: eui64
Queue Length (Tx/Rx): 1/1
Address: 192.168.20.10
fe80::7820:72ff:fe51:c1f8
Activation Policy: up
Required For Online: yes
DHCP6 Client DUID: DUID-EN/Vendor:0000ab116cb05daee96bb7a70000
Jul 25 21:11:48 ubuntu systemd-networkd[1074]: dummy0: netdev ready
Jul 25 21:11:48 ubuntu systemd-networkd[1074]: dummy0: Link UP
Jul 25 21:11:48 ubuntu systemd-networkd[1074]: dummy0: Gained carrier
Jul 25 21:11:48 ubuntu systemd-networkd[1074]: dummy0: Gained IPv6LL
ip -br addr show dummy0
dummy0 UNKNOWN 192.168.20.10/32 fe80::7820:72ff:fe51:c1f8/64
# Configure o BIRD:
cat << 'EOF' > /etc/bird/bird.conf
router id 192.168.15.10;
protocol direct {
ipv4;
ipv6;
interface "dummy*";
}
protocol device {
scan time 10;
}
function is_invalid_net() -> bool {
return net ~ [
192.168.20.10/32,
192.168.15.0/24,
0.0.0.0/0
];
}
filter kernel_out {
if is_invalid_net() then reject;
else accept;
}
protocol kernel {
ipv4 {
export filter kernel_out;
import none;
};
# importa rotas de volta ao BIRD:
learn;
scan time 20;
}
filter export_vip {
if net = 192.168.20.10/32 then accept;
reject;
}
protocol ospf v2 CLUSTER {
ipv4 {
import all;
export filter export_vip;
};
area 0.0.0.0 {
interface "eth0" {
type broadcast;
};
};
}
EOF
# Habilitar o Root no SSH para testar o load balance:
sed -i 's/#PermitRootLogin.*/PermitRootLogin yes/g' /etc/ssh/sshd_config
systemctl restart sshd ssh
# Reinicie o Bird:
systemctl restart bird
# Verifique os vizinhos OSPF:
birdc show ospf neighbors
#####################
# #
# ROUTER 13 #
# #
#####################
hostnamectl set-hostname server_13
cat << 'EOF' > /etc/netplan/01-cluster.yaml
network:
version: 2
ethernets:
eth0:
dhcp4: false
dhcp6: false
accept-ra: false
addresses:
- 192.168.15.13/24
routes:
- to: 0.0.0.0/0
via: 192.168.15.1
on-link: true
dummy0:
addresses:
- 192.168.20.10/32
EOF
# Vamos informar ao 'systemd-networkd' que existe uma interface chamada "dummy0":
cat << 'EOF' > /etc/systemd/network/dummy1.netdev
[NetDev]
Name=dummy0
Kind=dummy
EOF
# Aplique as configurações do Netplan:
netplan apply
# Reinicie o networkd:
systemctl restart systemd-networkd
# Verifique o status da Dummy0:
networkctl status dummy0
● 4: dummy0
Link File: /usr/lib/systemd/network/99-default.link
Network File: /run/systemd/network/10-netplan-dummy0.network
Type: ether
State: routable (configured)
Online state: online
Driver: dummy
HW Address: 7a:20:72:51:c1:f8
MTU: 1500
QDisc: noqueue
IPv6 Address Generation Mode: eui64
Queue Length (Tx/Rx): 1/1
Address: 192.168.20.10
fe80::7820:72ff:fe51:c1f8
Activation Policy: up
Required For Online: yes
DHCP6 Client DUID: DUID-EN/Vendor:0000ab116cb05daee96bb7a70000
Jul 25 21:11:48 ubuntu systemd-networkd[1074]: dummy0: netdev ready
Jul 25 21:11:48 ubuntu systemd-networkd[1074]: dummy0: Link UP
Jul 25 21:11:48 ubuntu systemd-networkd[1074]: dummy0: Gained carrier
Jul 25 21:11:48 ubuntu systemd-networkd[1074]: dummy0: Gained IPv6LL
# Configure o BIRD:
cat << 'EOF' > /etc/bird/bird.conf
router id 192.168.15.13;
protocol direct {
ipv4;
ipv6;
interface "dummy*";
}
protocol device {
scan time 10;
}
function is_invalid_net() -> bool {
return net ~ [
192.168.20.10/32,
192.168.15.0/24,
0.0.0.0/0
];
}
filter kernel_out {
if is_invalid_net() then reject;
else accept;
}
protocol kernel {
ipv4 {
export filter kernel_out;
import none;
};
# importa rotas de volta ao BIRD:
learn;
scan time 20;
}
filter export_vip {
if net = 192.168.20.10/32 then accept;
reject;
}
protocol ospf v2 CLUSTER {
ipv4 {
import all;
export filter export_vip;
};
area 0.0.0.0 {
interface "eth0" {
type broadcast;
};
};
}
EOF
# Habilitar o Root no SSH para testar o load balance:
sed -i 's/#PermitRootLogin.*/PermitRootLogin yes/g' /etc/ssh/sshd_config
systemctl restart sshd ssh
# Reinicie o Bird:
systemctl restart bird
# Verifique os vizinhos OSPF:
birdc show ospf neighbors
#####################
# #
# ROUTER 14 #
# #
#####################
hostnamectl set-hostname server_14
cat << 'EOF' > /etc/netplan/01-cluster.yaml
network:
version: 2
ethernets:
eth0:
dhcp4: false
dhcp6: false
accept-ra: false
addresses:
- 192.168.15.14/24
routes:
- to: 0.0.0.0/0
via: 192.168.15.1
on-link: true
dummy0:
addresses:
- 192.168.20.10/32
EOF
# Vamos informar ao 'systemd-networkd' que existe uma interface chamada "dummy0":
cat << 'EOF' > /etc/systemd/network/dummy1.netdev
[NetDev]
Name=dummy0
Kind=dummy
EOF
# Aplique as configurações do Netplan:
netplan apply
# Reinicie o networkd:
systemctl restart systemd-networkd
# Verifique o status da Dummy0:
networkctl status dummy0
● 4: dummy0
Link File: /usr/lib/systemd/network/99-default.link
Network File: /run/systemd/network/10-netplan-dummy0.network
Type: ether
State: routable (configured)
Online state: online
Driver: dummy
HW Address: 7a:20:72:51:c1:f8
MTU: 1500
QDisc: noqueue
IPv6 Address Generation Mode: eui64
Queue Length (Tx/Rx): 1/1
Address: 192.168.20.10
fe80::7820:72ff:fe51:c1f8
Activation Policy: up
Required For Online: yes
DHCP6 Client DUID: DUID-EN/Vendor:0000ab116cb05daee96bb7a70000
Jul 25 21:11:48 ubuntu systemd-networkd[1074]: dummy0: netdev ready
Jul 25 21:11:48 ubuntu systemd-networkd[1074]: dummy0: Link UP
Jul 25 21:11:48 ubuntu systemd-networkd[1074]: dummy0: Gained carrier
Jul 25 21:11:48 ubuntu systemd-networkd[1074]: dummy0: Gained IPv6LL
# Configure o BIRD:
cat << 'EOF' > /etc/bird/bird.conf
router id 192.168.15.14;
protocol direct {
ipv4;
ipv6;
interface "dummy*";
}
protocol device {
scan time 10;
}
function is_invalid_net() -> bool {
return net ~ [
192.168.20.10/32,
192.168.15.0/24,
0.0.0.0/0
];
}
filter kernel_out {
if is_invalid_net() then reject;
else accept;
}
protocol kernel {
ipv4 {
export filter kernel_out;
import none;
};
# importa rotas de volta ao BIRD:
learn;
scan time 20;
}
filter export_vip {
if net = 192.168.20.10/32 then accept;
reject;
}
protocol ospf v2 CLUSTER {
ipv4 {
import all;
export filter export_vip;
};
area 0.0.0.0 {
interface "eth0" {
type broadcast;
};
};
}
EOF
# Habilitar o Root no SSH para testar o load balance:
sed -i 's/#PermitRootLogin.*/PermitRootLogin yes/g' /etc/ssh/sshd_config
systemctl restart sshd ssh
# Reinicie o Bird:
systemctl restart bird
# Verifique os vizinhos OSPF:
birdc show ospf neighbors
Entendendo a Configuração dos Servers
Nos servidores do cluster, configuramos uma interface chamada dummy com um IP virtual (VIP) compartilhado entre todos os nós e ativamos o OSPF com o BIRD para anunciar esse IP ao roteador. Essa é a premissa básica para o balanceamento.
addresses:
- 192.168.15.10/24
routes:
- to: 0.0.0.0/0
via: 192.168.15.1
on-link: true
Na configuração acima, estamos configurando o IP 192.168.15.10/24 na interface física eth0, que será usada para que esse servidor possa se comunicar com o Router, e será o nexthop do OSPF. Cada servidor terá um endereço IP diferente.
A rota padrão (0.0.0.0/0) aponta para o roteador (192.168.15.1). A opção on-link: true informa ao sistema que o gateway está diretamente acessível, mesmo sem ARP, o que é útil em ambientes onde nem sempre há resposta ARP no momento da inicialização.
dummy0:
addresses:
- 192.168.20.10/32
Já na configuração acima, a interface dummy0 é uma interface virtual local ao kernel, que simula uma interface de rede. Ela é usada aqui para atribuir um IP virtual (VIP) ao servidor sem precisar de um endereço físico. Pense na dummy0 como uma interface de loopback, mas sem as restrições especiais que o sistema operacional impõe à lo. Ela permite atribuir um IP local ao host, como a lo, mas aceita tráfego vindo de outras máquinas e pode participar normalmente do roteamento.
O /32 indica que esse IP é um isolado, isso fará com que o kernel não tente realizar comunicação ARP com esse endereço. Esse IP deve ser o mesmo em todos os servidores do cluster. O roteador verá múltiplos caminhos OSPF válidos para a VIP, com o mesmo custo, o que ativa o ECMP.
[NetDev]
Name=dummy0
Kind=dummy
O arquivo acima (/etc/systemd/network/dummy1.netdev) declara explicitamente a criação da interface dummy0 como sendo do tipo dummy. Isso é necessário para que o systemd-networkd saiba que a interface deve existir mesmo sem driver físico ou ligação real com hardware.
Bird - protocol direct
Essa diretiva detecta rotas diretamente conectadas em interfaces locais. Estamos limitando a atuação dele apenas às interfaces cujo nome começa com dummy, ou seja, nossa dummy0, que é onde está configurada a VIP 192.168.20.10. Também informa que o protocolo direct deve atuar sobre endereços IPv4 e IPv6.
Sem esse bloco, o BIRD não saberia que esse IP /32 existe na máquina e não poderia exportá-lo para o OSPF. Ele também evita importar rotas das demais interfaces físicas, queremos que o BIRD enxergue apenas a VIP, e não toda a topologia da máquina.
protocol direct {
ipv4;
ipv6;
interface "dummy*";
}
Bird - protocol device
Esse protocolo é responsável por monitorar o estado das interfaces de rede. Ele precisa estar ativado para que o BIRD perceba quando uma interface (como a dummy0 ou a eth0) fica up ou down, e possa reagir, como reiniciar sessões OSPF, recalcular rotas, ou parar de anunciar prefixos.
O scan time 10 diz para o BIRD verificar as interfaces a cada 10 segundos.
protocol device {
scan time 10;
}
Bird - function is_invalid_net() + filter kernel_out
Aqui estamos criando uma função auxiliar (function is_invalid_net()) que retorna verdadeiro para redes que não devem ser exportadas para o kernel. São elas:
192.168.20.10/32: já está configurada localmente nadummy0, não precisa ser reenviada.192.168.15.0/24: é a rede local da interfaceeth0.0.0.0.0/0: rota default, não queremos instalar no kernel.
Em seguida, usamos um filtro (que chamamos de kernel_out) no protocolo kernel abaixo para garantir que apenas rotas válidas sejam repassadas ao sistema operacional.
function is_invalid_net() -> bool {
return net ~ [
192.168.20.10/32,
192.168.15.0/24,
0.0.0.0/0
];
}
filter kernel_out {
if is_invalid_net() then reject;
else accept;
}
Resumindo, se a rota estiver listada em is_invalid_net(), ela será rejeitada pelo filtro kernel_out. Portanto, não será exportada para o kernel. Não queremos enviar essas rotas para o Kernel porque duas ele já tem e não queremos sobrescrever a rota default.
Bird - protocol kernel
Esse protocolo faz a sincronização entre o BIRD e a tabela de roteamento do sistema. As seguintes opções foram usadas:
import none: não queremos que o BIRD aprenda rotas do sistema (ex: rotas DHCP, estáticas locais etc.).export filter kernel_out: exporta para o kernel somente rotas válidas, segundo o filtro que definimos acima.learn: permite que rotas vindas do kernel que já estavam lá sejam reconhecidas como aprendidas.scan time 20: define a frequência de sincronização entre BIRD e kernel.
Essa separação evita loops ou comportamentos imprevisíveis caso rotas entrem e saiam da tabela de forma automática.
protocol kernel {
ipv4 {
export filter kernel_out;
import none;
};
learn;
scan time 20;
}
Bird - filter export_vip
Esse filtro garante que o BIRD anuncie apenas a VIP via OSPF. Isso é fundamental em ECMP com servidores com IP compartilhado, ele vai:
- Garantir que a rota
/32da VIP seja exportada no OSPF. - Impedir que outras rotas locais, como
192.168.15.0/24oulo, sejam acidentalmente anunciadas.
filter export_vip {
if net = 192.168.20.10/32 then accept;
reject;
}
Bird - protocol ospf v2 CLUSTER
Este é o bloco principal que ativa o OSPF v2 (para IPv4) no servidor. As seguintes opções foram usadas:
import all: aceita todas as rotas recebidas via OSPF (por exemplo, a VIP anunciada por outros servidores).export filter export_vip: exporta apenas a VIP local para os vizinhos OSPF, usando o filtro que definimos anteriormente.interface "eth0": define que o OSPF rodará na interface física que liga os servidores ao roteador.type broadcast: OSPF usará modo broadcast (com eleição de DR/BDR), que é o tipo certo para redes Ethernet ou bridges.
O nome CLUSTER é só um identificador para o protocolo dentro do BIRD, pode ser qualquer nome.
protocol ospf v2 CLUSTER {
ipv4 {
import all;
export filter export_vip;
};
area 0.0.0.0 {
interface "eth0" {
type broadcast;
};
};
}
Configurando o Router
Para que o balanceamento funcione corretamente com algumas aplicações, é necessário configurar o CEF (Cisco Express Forwarding). O CEF é o mecanismo de encaminhamento de pacotes padrão em roteadores Cisco, projetado para melhorar o desempenho e escalabilidade do roteamento, especialmente em ambientes com tráfego intenso.
O CEF mantém duas estruturas principais:
FIB (Forwarding Information Base) Uma versão otimizada da tabela de roteamento. Contém a decisão final de encaminhamento para cada destino.
Adjacency Table Armazena as informações de próximo salto, como o endereço MAC e a interface de saída, já prontas para o encapsulamento.
Essas tabelas permitem que o roteador encaminhe pacotes de forma eficiente, sem consultar a tabela de roteamento a cada novo pacote. Porém, por padrão, o algoritmo de balanceamento do CEF usa apenas o IP de origem e o IP de destino para calcular o hash. Isso pode ser um problema em cenários onde múltiplos fluxos têm o mesmo destino, como quando se usa um mesmo endereço, como nosso IP virtual nos servidores.
Para que o tráfego seja devidamente distribuído entre os caminhos disponíveis, podemos alterar o algoritmo do CEF para incluir também as portas de origem e destino (camada 4) no cálculo do hash. Isso garante que fluxos distintos, mesmo indo para o mesmo IP, tenham mais chance de seguir por caminhos diferentes.
enable
conf t
!
! Ativando o CEF
ip cef
!
! Configurando o
ip cef load-sharing algorithm include-ports source destination
!
hostname router_ecmp
!
interface Loopback0
ip address 10.255.0.1 255.255.255.255
!
interface GigabitEthernet0/1
description CLiente de teste
ip address 172.16.0.1 255.255.255.0
no shut
!
interface GigabitEthernet0/0
description Cluster LAN Servidores
ip address 192.168.15.1 255.255.255.0
ip ospf 1 area 0
no shut
!
! Configura o mesmo custo em todos os caminhos
ip ospf cost 10
!
router ospf 1
router-id 192.168.15.1
network 192.168.15.0 0.0.0.255 area 0
passive-interface Loopback0
end
wr
Para verificar se as sessões OSPF estão ativas podemos usar o comando abaixo:
router_ecmp#show ip ospf neighbor
Neighbor ID Pri State Dead Time Address Interface
192.168.15.10 1 FULL/BDR 00:00:32 192.168.15.10 GigabitEthernet0/0
192.168.15.12 1 FULL/DROTHER 00:00:34 192.168.15.12 GigabitEthernet0/0
192.168.15.13 1 FULL/DROTHER 00:00:30 192.168.15.13 GigabitEthernet0/0
192.168.15.14 1 FULL/DROTHER 00:00:32 192.168.15.14 GigabitEthernet0/0
Agora podemos verificar as rotas recebidas via OSPF:
router_ecmp#show ip route ospf | begin Gateway
Gateway of last resort is not set
192.168.20.0/32 is subnetted, 1 subnets
O E2 192.168.20.10
[110/10000] via 192.168.15.14, 00:24:57, GigabitEthernet0/0
[110/10000] via 192.168.15.13, 00:27:42, GigabitEthernet0/0
[110/10000] via 192.168.15.12, 00:30:38, GigabitEthernet0/0
[110/10000] via 192.168.15.10, 00:43:17, GigabitEthernet0/0
Como podemos ver, estamos aprendendo a mesma rota (192.168.20.10/32) de todos os servidores, com o mesmo custo, o que habilita o balanceamento ECMP. Também é possível observar que todos os nexthops pertencem à rede do cluster, onde cada servidor publica a VIP por meio de uma interface dummy.
O E2Quando cada servidor injeta a VIP 192.168.20.10/32 no OSPF, ele atua como ASBR (redistribuindo uma rota que não veio do próprio OSPF, que no caso está conectado na dummy0). Em área normal (não‑stub), isso gera uma LSA Externa Tipo 5, que por padrão, sai como E2.
Isso implica em algumas questões importantes para nosso cenário:
- E2 (External Type 2) usa somente a métrica externa para escolher rotas. O custo interno até o ASBR não é somado na métrica, mas é levado em conta como forward metric para desempate.
- Se métrica externa empata e o forward metric empata, o roteador instala ECMP com vários next‑hops. É exatamente o que queremos para distribuir carga entre servidores.
- Em muitos daemons, a métrica externa padrão é 10000, o que explica saídas como
O E2 192.168.20.10/32 [110/10000] ... forward metric 10.
Devemos considerar E1?
- O E1 (External Type 1) soma custo interno + externo. Será útil se quisermos acessar o servidor "mais perto", quando os custos internos forem diferentes.
- Para o nosso cenário simétrico (custos iguais até cada nó), E2 é suficiente e tende a gerar menos churn no SPF.
Vamos inspecionar como o CEF está tratando o encaminhamento:
router_ecmp#show ip cef 192.168.20.10 detail
192.168.20.10/32, epoch 0, per-destination sharing
nexthop 192.168.15.10 GigabitEthernet0/0
nexthop 192.168.15.12 GigabitEthernet0/0
nexthop 192.168.15.13 GigabitEthernet0/0
nexthop 192.168.15.14 GigabitEthernet0/0
O CEF reconhece todos os servidores como nexthops válidos para a VIP, o que confirma que o balanceamento está ativo. Podemos ainda validar a rota da VIP com:
router_ecmp#show ip route 192.168.20.10
Routing entry for 192.168.20.10/32
Known via "ospf 1", distance 110, metric 10000, type extern 2, forward metric 10
Last update from 192.168.15.14 on GigabitEthernet0/0, 00:02:42 ago
Routing Descriptor Blocks:
192.168.15.14, from 192.168.15.14, 00:02:42 ago, via GigabitEthernet0/0
Route metric is 10000, traffic share count is 1
192.168.15.13, from 192.168.15.13, 00:05:27 ago, via GigabitEthernet0/0
Route metric is 10000, traffic share count is 1
192.168.15.12, from 192.168.15.12, 00:08:23 ago, via GigabitEthernet0/0
Route metric is 10000, traffic share count is 1
* 192.168.15.10, from 192.168.15.10, 00:21:02 ago, via GigabitEthernet0/0
Route metric is 10000, traffic share count is 1
Com isso, temos o CEF devidamente configurado para distribuir os fluxos entre múltiplos servidores, mesmo quando todos anunciam o mesmo IP virtual. Ao incluir as portas no algoritmo de hash, garantimos que diferentes conexões possam ser balanceadas entre os caminhos disponíveis.
Testes no Cliente
Vamos utilizar a máquina cliente para validar se o balanceamento de carga está funcionando corretamente. A ideia é realizar várias conexões SSH para o IP virtual 192.168.20.10 e executar o comando hostname em cada uma delas.
Como esse IP é compartilhado por todos os servidores do cluster via interface dummy, o servidor que responder será determinado pelo algoritmo de hash do CEF. A cada nova conexão, se o balanceamento estiver funcionando, devemos ver nomes de host diferentes:
alpine:~# ssh root@192.168.20.10 hostname
root@192.168.20.10's password:
server10
alpine:~# ssh root@192.168.20.10 hostname
root@192.168.20.10's password:
server13
alpine:~# ssh root@192.168.20.10 hostname
root@192.168.20.10's password:
server12
alpine:~# ssh root@192.168.20.10 hostname
root@192.168.20.10's password:
server14
Como podemos ver, cada conexão foi roteada para um servidor diferente, confirmando que o balanceamento de carga via ECMP está funcionando conforme esperado. Devido ao algoritmo de hash do CEF, é possível que um único servidor receba múltiplas conexões consecutivas. No entanto, novas conexões com combinações diferentes de portas e IPs tendem a ser distribuídas entre os demais servidores disponíveis.