Full Mesh
Sendo bem direto, o Full mesh (malha completa), é uma topologia em que cada nó tem conexão direta com todos os demais.
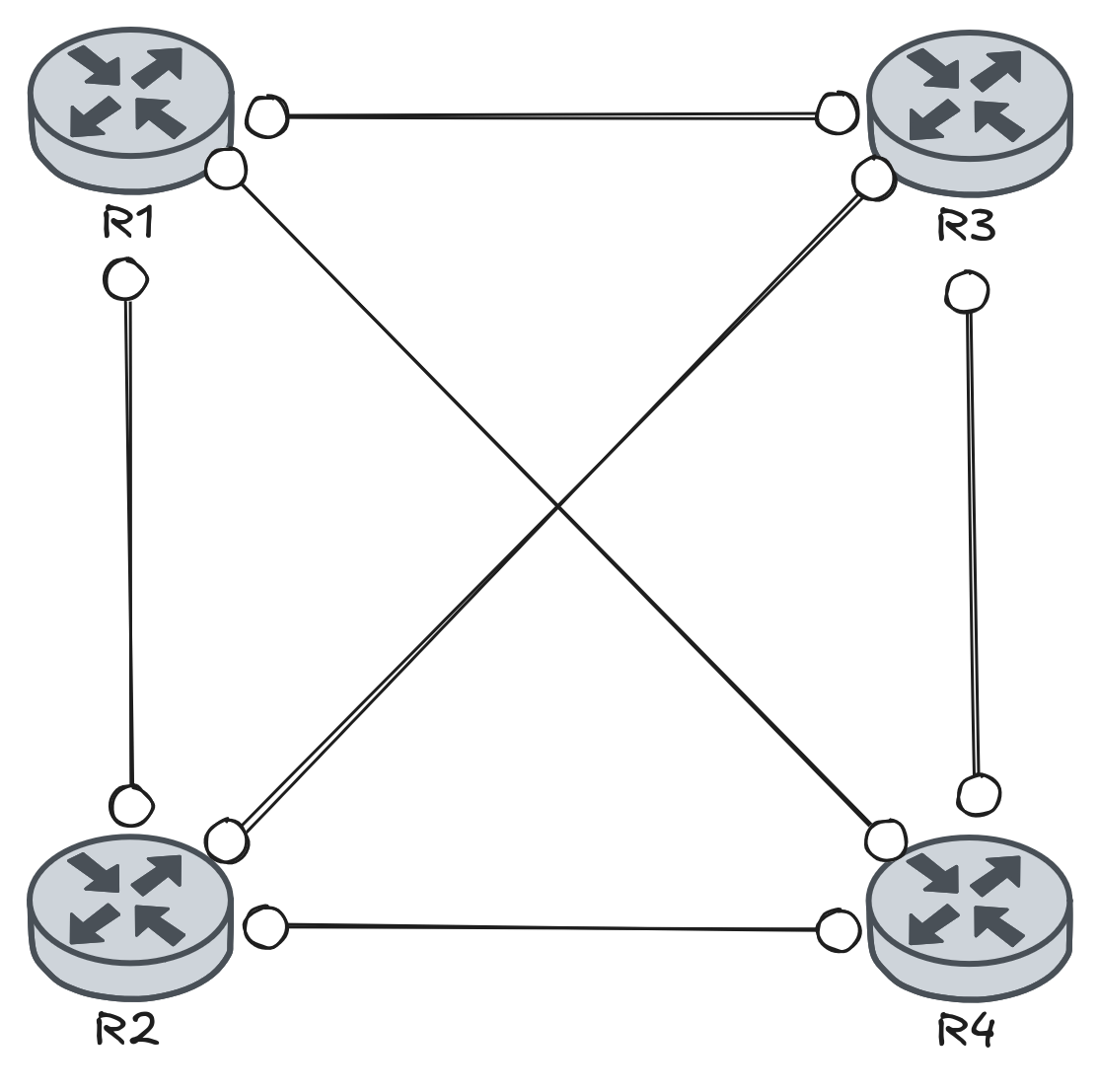
A imagem acima ilustra uma topologia full mesh.
Para ser considerado Full Mesh, cada nó possui ligação direta com todos os demais. Se algum par não tiver link direto, a topologia é considerada Partial Mesh. A vantagem dessa topologia é que exsitem múltiplos caminhos diretos, a resiliência é boa e possui baixa latência entre os pares.
Como nem tudo são flores, o número de conexões pode crescer muito rápido e dificultar a administração. O custo/complexidade também cresce na mesma medida. É ótima para poucos nós, mas inviável quando a malha cresce.
Em iBGP, full mesh não é usado para falar sobre as ligações físicas como na topologia, e sim à malha de sessões, onde cada roteador estabelece sessão iBGP com todos os demais. Isso existe porque rotas aprendidas via iBGP não são reanunciadas a outro vizinho iBGP.
Para que isso ocorra, não é preciso ter enlaces físicos ponto a ponto entre todos os roteadores. Basta ter alcançabilidade IP na rede interna e formar as sessões entre loopbacks com update-source e, quando necessário, next-hop-self.
iBGP Full Mesh Requirement
O iBGP Full Mesh Requirement é uma regra fundamental do protocolo BGP (Border Gateway Protocol) quando utilizado internamente entre roteadores de um mesmo sistema autônomo (iBGP). Essa regra define que:
- Todos os roteadores iBGP devem estabelecer sessões BGP entre si (full mesh), já que, rotas aprendidas por iBGP não serão propagadas para os demais roteadores iBGP.
Essa regra foi criada para evitar loops de roteamento. Como o BGP não utiliza um mecanismo interno como o OSPF ou o IS-IS para garantir ausência de loops, a RFC 4271 estabelece esse requisito para o iBGP:
- Um roteador não propaga para um peer iBGP rotas que ele mesmo aprendeu de outro peer iBGP. Isso significa que, sem full mesh (lógico e não físico), uma rota pode entrar em um roteador e ficar "presa" ali, os outros roteadores do AS não ficam sabendo dela.
Vamos usar a imagem abaixo como exemplo:
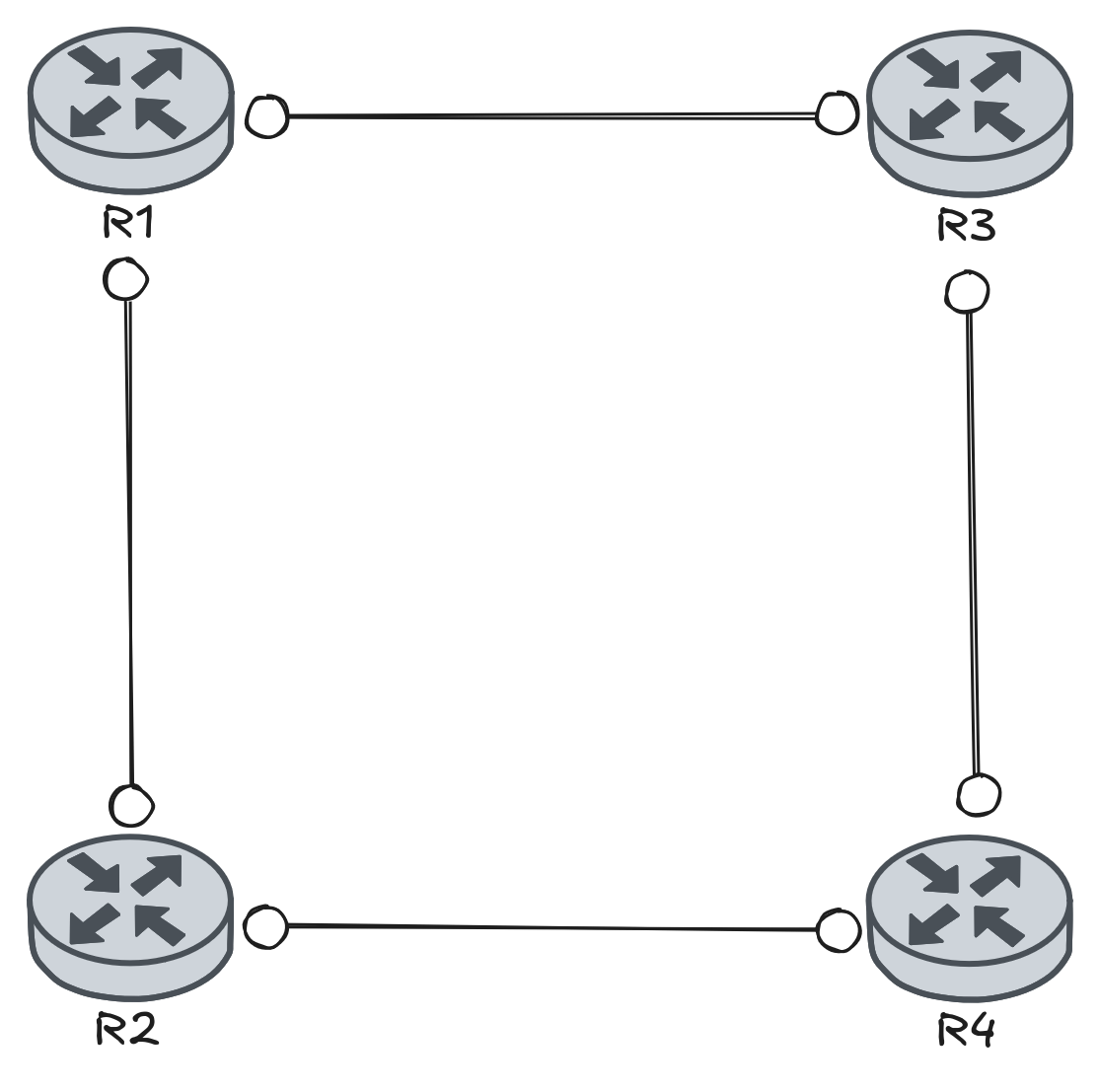
A imagem acima ilustra uma topologia Partial mesh. Image sessões iBGP e não ligações ponto a ponto.
Como não existe sessão entre R1 e R4 / R2 e R3, se R1 aprender um prefixo e enviar para R2, o R2 não pode enviar esse prefixo para R4 via iBGP. O resultado é simples, R4 nunca verá a rota aprendida por R1.
Soluções alternativas
Como o número de sessões iBGP cresce rapidamente com o número de roteadores, duas soluções comuns são usadas para evitar o full mesh:
Route Reflector (RR)
Um roteador atua como refletor e pode repassar rotas iBGP para outros clientes. Isso reduz drasticamente o número de sessões em todos os roteadores.
Confederação BGP
Divide um grande AS em sub-AS internos, que se comunicam como se fossem eBGP, mas externamente aparecem como um único AS. É mais complexo, mas útil em ambientes muito grandes.
Loopback em iBGP para Full Mesh
Em uma topologia iBGP Full Mesh, é boa prática utilizar o IP da interface loopback para estabelecer as sessões BGP, e não o IP de uma interface física. Isso garante maior resiliência.
Se você usar o IP de uma interface física (como eth0) e essa interface cair, a sessão iBGP também cairá, mesmo que existam outros caminhos no roteamento para alcançar o roteador vizinho. Isso acontece porque o BGP considera o IP de origem e de destino como diretamente dependentes da interface configurada.
A interface loopback nunca cai (a menos que o roteador pare), e você pode alcançá-la por qualquer caminho válido presente na tabela de roteamento. Por isso, a loopback oferece estabilidade para a sessão BGP.
Como os peers iBGP precisam se alcançar via o IP da loopback, é necessário anunciar a loopback nos protocolos de roteamento interno, como OSPF ou IS-IS. Não se deve usar iBGP para anunciar a loopback que será usada no próprio iBGP, isso criaria um problema de "ovo e galinha".
Suponha que o Router 2 tenha a loopback 192.168.2.2. No Router 1, configuramos o iBGP da seguinte forma:
# router 1
router bgp 65001
neighbor 192.168.2.2 remote-as 65001
neighbor 192.168.2.2 update-source Loopback0
O remote-as 65001 indica que é um vizinho iBGP (se ambos os routers tiverem o mesmo ASN). Já o update-source Loopback0, vai forçar o uso da interface loopback como IP de origem da sessão BGP. Essa configuração deve ser feita em ambos os lados, e a rota para a loopback do outro peer precisa estar presente no roteador (via OSPF, IS-IS, ou rota estática).
Como curiosidade, abaixo podemos ver o OSPF usado para anunciar a loopback:
# Router 1:
router ospf 1
network 192.168.1.1 0.0.0.0 area 0
# Router 2:
router ospf 1
network 192.168.2.2 0.0.0.0 area 0
É necessário anunciar as interfaces ponto a ponto, mas não coloquei no exemplo acima.
A prática de usar loopback vale para qualquer sessão iBGP, independentemente de ser uma topologia Full Mesh, com Route Reflectors ou Confederação. A motivação é sempre a mesma, garantir estabilidade e não depender de uma interface física única.
Para exemplificar vamos usar o exemplo abaixo para subir os routers:
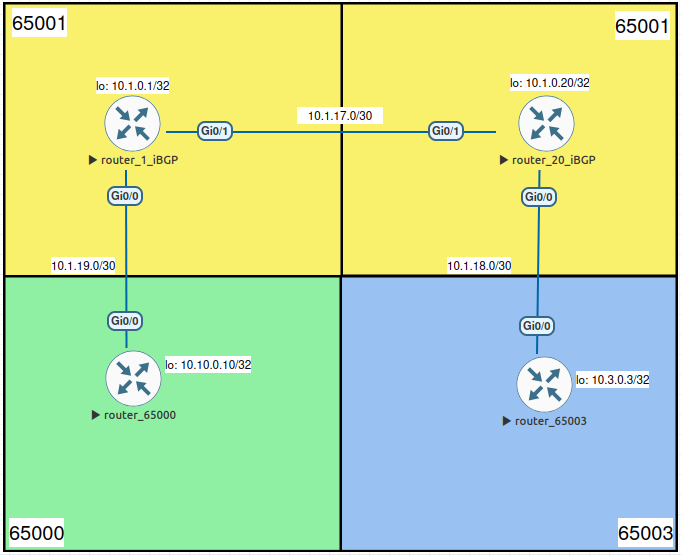
A imagem acima ilustra uma topologia Partial mesh, vamos usar para subir sessões eBGP e iBGP.
Configurando Router 65000
enable
conf t
no ip domain lookup
!
hostname router_65000
!
interface Loopback0
ip address 10.10.0.10 255.255.255.255
!
interface GigabitEthernet0/0
description iBGP com Router_65001
ip address 10.1.19.2 255.255.255.252
no shut
!
interface GigabitEthernet0/2
description LAN
ip address 172.16.10.1 255.255.255.0
no shut
!
router bgp 65000
bgp router-id 10.10.0.10
neighbor 10.1.19.1 remote-as 65001
!
address-family ipv4
network 172.16.10.0 mask 255.255.255.0
network 10.10.0.10 mask 255.255.255.255
neighbor 10.1.19.1 activate
exit-address-family
!
end
wr
Configurando router_1_iBGP - 10.1.0.1
enable
conf t
no ip domain lookup
!
hostname router_1_iBGP
!
interface Loopback0
ip address 10.1.0.1 255.255.255.255
!
interface GigabitEthernet0/0
description iBGP com Router_65000
ip address 10.1.19.1 255.255.255.252
no shut
!
interface GigabitEthernet0/1
description BGP com router_65001_iBGP
ip address 10.1.17.1 255.255.255.252
no shut
ip ospf 1 area 0
ip ospf network point-to-point
!
interface GigabitEthernet0/2
description LAN
ip address 192.168.1.1 255.255.255.0
no shut
!
router ospf 1
network 10.1.0.1 0.0.0.0 area 0
passive-interface GigabitEthernet0/0
passive-interface GigabitEthernet0/2
!
router bgp 65001
bgp router-id 10.1.0.1
neighbor 10.1.0.20 remote-as 65001
neighbor 10.1.0.20 update-source Loopback0
neighbor 10.1.19.2 remote-as 65000
!
address-family ipv4
network 192.168.1.0 mask 255.255.255.0
neighbor 10.1.0.20 activate
neighbor 10.1.19.2 activate
exit-address-family
!
end
wr
Lembre-se de que, ao usar loopbacks nas sessões BGP, os vizinhos precisam ter uma rota válida até a nossa loopback e conseguir alcançá-la via um próximo salto (next-hop) acessível. Por exemplo, para chegar à loopback 10.1.0.1, o roteador vizinho deve ter uma rota apontando para os IPs 10.1.17.1 ou 10.1.19.1 como next-hop, dependendo de qual interface conecta ao nosso roteador.
Configurando router_2_iBGP - 10.1.0.20
enable
conf t
no ip domain lookup
!
hostname router_20_iBGP
!
interface Loopback0
ip address 10.1.0.20 255.255.255.255
!
interface GigabitEthernet0/0
description BGP com Router_65003
ip address 10.1.18.1 255.255.255.252
no shut
!
interface GigabitEthernet0/1
description BGP com router_65001_iBGP
ip address 10.1.17.2 255.255.255.252
no shut
ip ospf 1 area 0
ip ospf network point-to-point
!
interface GigabitEthernet0/2
description LAN
ip address 192.168.2.1 255.255.255.0
no shut
!
router ospf 1
network 10.1.0.20 0.0.0.0 area 0
passive-interface GigabitEthernet0/0
passive-interface GigabitEthernet0/2
!
router bgp 65001
bgp router-id 10.1.0.20
neighbor 10.1.0.1 remote-as 65001
neighbor 10.1.0.1 update-source Loopback0
neighbor 10.1.18.2 remote-as 65003
!
address-family ipv4
network 192.168.2.0 mask 255.255.255.0
neighbor 10.1.0.1 activate
neighbor 10.1.18.2 activate
exit-address-family
!
end
wr
Configurando Router 3
enable
conf t
no ip domain lookup
!
hostname router_65003
!
interface Loopback0
ip address 10.3.0.3 255.255.255.255
!
interface GigabitEthernet0/0
description BGP com Router_65002
ip address 10.1.18.2 255.255.255.252
no shut
!
interface GigabitEthernet0/2
description LAN
ip address 192.168.3.1 255.255.255.0
no shut
!
router bgp 65003
bgp router-id 10.3.0.3
neighbor 10.1.18.1 remote-as 65001
!
address-family ipv4
network 192.168.3.0 mask 255.255.255.0
neighbor 10.1.18.1 activate
exit-address-family
!
end
wr
Problema do NEXT_HOP no iBGP
Em iBGP, quando um roteador de borda aprende rotas via eBGP e as repassa para um vizinho interno, o NEXT_HOP é preservado. Isso significa que a rota chega ao par iBGP apontando para o endereço do vizinho externo, que não faz parte do IGP. Se o IGP não souber alcançar esse endereço, a rota aparece na tabela BGP como inválida ou inacessível, ainda que o anúncio esteja presente.
A causa está no próprio comportamento do BGP. Rotas eBGP mantêm o NEXT_HOP ao serem anunciadas para iBGP. Sem intervenção, o roteador interno não tem como chegar ao next hop que vive fora do seu domínio de roteamento.
No router_20_iBGP a rota para 10.10.0.10 chega pelo iBGP (enviada pelo router_1_iBGP que recebeu via eBGP), porém, o router_20_iBGP não tem rota válida até o next hop de 10.10.0.10 (O nexthop é 10.1.19.2). Abaixo podemos ver isso:
router_20_iBGP#show ip bgp ipv4 unicast 10.10.0.10
BGP routing table entry for 10.10.0.10/32, version 0
Paths: (1 available, no best path)
65000
10.1.19.2 (inaccessible) from 10.1.0.1 (10.1.0.1)
... valid, internal
Como o next hop é 10.1.19.2, e não temos rota para esse next hop (está como inaccessible), não conseguimos chegar até 10.10.0.10. No router_1_iBGP a mesma rota está perfeita, porque ali ela foi aprendida diretamente via eBGP e o next hop 10.1.19.2 é alcançável pelo enlace externo
router_1_iBGP#show ip bgp ipv4 unicast 10.10.0.10
Paths: (1 available, best #1, table default)
65000
10.1.19.2 from 10.1.19.2 (10.10.0.10)
... valid, external, best
Em outras palavras, a borda do lado do provedor 65000 enxerga a rota e a considera melhor, mas ao anunciar para o iBGP, preserva o next hop externo, deixando o par interno sem ter como chegar nessa rota. No router_65003 a rede nem aparece na tabela:
router_65003#show ip bgp ipv4 unicast 10.10.0.10
% Network not in table
Isso acontece porque o router_20_iBGP não consegue instalar a rota como best e, sem best, não há o que anunciar adiante para o eBGP com o AS 65003.
Para resolver esse problema, existem algumas abordagens, vou descrever as que consigo lembrar, mas vale reforçar que uma delas é a melhor prática e você deve adotar ela, outra é aceitavel para ambientes pequenos/médio, são eles:
Anunciar os enlaces ponto a ponto no BGP
Consiste em injetar no BGP as sub‑redes dos links de peering (inclusive as externas) para que os roteadores internos "aprendam" a alcançar o next hop externo via BGP.
Vantagen:
- Pode até "funcionar".
Desvantagens:
- É má prática, polui a tabela com rotas de infraestrutura, aumenta churn e risco de vazamento para fora do AS.
- Não resolve de forma limpa quando o next hop está em uma rede que pertence ao provedor.
- Dificulta sumarização e controle de políticas.
- Nunca faça isso!
Usar IGP para publicação de rotas
A parte correta é anunciar no IGP apenas as loopbacks e os enlaces internos entre os roteadores iBGP, garantindo alcançabilidade interna das sessões. Isso, por si só, não resolve o problema do NEXT_HOP preservado. Resolveria apenas se você também colocasse o enlace externo (com o provedor) no IGP, o que é indesejado.
Vantagens:
- Recomendado para anunciar as loopbacks e para escolha de caminhos internos.
- Mantém o controle de alcance interno sob o IGP.
Desvantagens:
- Se incluir enlaces externos no IGP, você acopla domínios administrativos, aumenta a superfície de falhas e "vaza" a malha interna até o provedor.
- Mesmo com IGP bem feito (apenas interno), o NEXT_HOP externo continua inalcançável sem outra medida. Isso ocorre porque o eBGP pode não conhecer o caminho de volta, então o tráfego até chega nele, mas não consegue voltar.
Criar rota estática para o next hop externo
Exemplo típico, no roteador
router_20_iBGP, cria-se uma rota estática para o endereço do vizinho eBGP dorouter_1_iBGP, apontando para orouter_1_iBGP.Vantagens:
- Simples de entender e implementar em cenários pequenos.
- Resolve imediatamente o status "inaccessible" do next hop.
Desvantagens:
- Não escala, você precisar de uma rota estática por next hop externo, por borda, por cenário, vai ficar muito complexo de administrar.
- Frágil a mudanças e falhas. Com tracking/BFD, cresce a complexidade operacional.
Ajustar o next hop com
next-hop-self(recomendado)O roteador de borda reescreve o NEXT_HOP quando anuncia a rota no iBGP, trocando o endereço externo pelo próprio endereço interno (normalmente a loopback). Assim, todos enxergam um next hop interno e alcançável via IGP.
Vantagens:
- Solução limpa, contida e escalável.
- Mantém o IGP restrito ao AS e evita vazar infraestrutura.
- Facilita operações, independentemente de quantos vizinhos eBGP você tenha.
Desvantagens:
- Em redes com múltiplas saídas externas e política de "hot‑potato" muito estrita,
next-hop-selfmuda a base de comparação para o custo IGP até o par iBGP (em vez do custo até o next hop eBGP). Na maioria dos ambientes isso é desejável, em arquiteturas muito grandes pode exigir desenho adicional (por exemplo, MPLS/BGP‑LU ou políticas específicas).
Ajustar o next hop com next-hop-self
Vamos adotar essa medida e ver que o problema se resolverá:
# Fazer isso no router_1_iBGP:
enable
conf t
!
router bgp 65001
address-family ipv4
neighbor 10.1.0.20 next-hop-self
exit-address-family
!
end
wr
No par do outro lado a configuração é simétrica, ou seja, depois de aplicado, as rotas externas aparecem com next hop interno, a sessão fica estável mesmo sem rotas para endereços de vizinhos eBGP no IGP, e a rede preserva a separação saudável entre IGP e BGP. Em uma checagem rápida, show ip bgp deve exibir as rotas com NEXT_HOP igual à loopback do par iBGP.
Agora temos que fazer o mesmo para os prefixos que o router_65003 envia para o router_20_iBGP, assim ele pode propagar para router_1_iBGP e ele enviar para o router_65000:
# Fazer isso no router_20_iBGP:
enable
conf t
!
router bgp 65001
address-family ipv4
neighbor 10.1.0.1 next-hop-self
exit-address-family
!
end
wr
No Router_1-iBGP nada muda:
router_1_iBGP#show ip bgp ipv4 unicast 10.10.0.10
BGP routing table entry for 10.10.0.10/32, version 2
Paths: (1 available, best #1, table default)
Advertised to update-groups:
3
Refresh Epoch 1
65000
10.1.19.2 from 10.1.19.2 (10.10.0.10)
Origin IGP, metric 0, localpref 100, valid, external, best
rx pathid: 0, tx pathid: 0x0
Agora no router 2 podemos ver as mudanças:
router_10.1.0.20_iBGP#show ip bgp ipv4 unicast 10.10.0.10
BGP routing table entry for 10.10.0.10/32, version 5
Paths: (1 available, best #1, table default)
Advertised to update-groups:
2
Refresh Epoch 1
65000
10.1.0.1 (metric 2) from 10.1.0.1 (10.1.0.1)
Origin IGP, metric 0, localpref 100, valid, internal, best
rx pathid: 0, tx pathid: 0x0
E ate o router_65003 possui rota para la agora:
router_65003#show ip bgp ipv4 unicast 10.10.0.10
BGP routing table entry for 10.10.0.10/32, version 9
Paths: (1 available, best #1, table default)
Not advertised to any peer
Refresh Epoch 1
65001 65000
10.1.18.1 from 10.1.18.1 (10.1.0.20)
Origin IGP, localpref 100, valid, external, best
rx pathid: 0, tx pathid: 0x0
Como podemos ver, no Router_1‑iBGP nada muda, ele continua enxergando a rota 10.10.0.10/32 como a melhor, recebida diretamente via eBGP com next-hop para 10.1.19.2, o que é o comportamento esperado.
Já no Router_2_iBGP, observamos a principal diferença, a mesma rota agora é aprendida de um vizinho iBGP, com next-hop para 10.1.0.1. Essa rota é considerada best porque o next-hop é interno e alcançável. Essa alteração acontece porque estamos utilizando OSPF para divulgar as rotas de loopback, o que torna 10.1.0.1 um next-hop válido dentro do domínio IGP.
O metric 2 exibido no output reflete justamente o custo do caminho IGP até 10.1.0.1.
No Router_65003, a rota também passa a aparecer, agora com AS-PATH "65001 65000" e next-hop para 10.1.18.1. Isso indica que o tráfego destinado a 10.10.0.10 encontra um caminho válido via o AS 65001, saindo corretamente pela borda.
Mas há um detalhe importante, ao testar conectividade a partir do router_65003 ou router_20_iBGP, você não deve usar como IP de origem um endereço dos links ponto a ponto. Se fizer isso, o pacote até chegará ao destino 10.10.0.10, mas não conseguirá voltar. Isso ocorre porque o router_65000 não conhece os links ponto a ponto, já que eles não foram anunciados no BGP.
Para garantir que o tráfego tenha caminho de volta, você deve utilizar como origem um IP pertencente a uma das redes LAN, pois todas elas foram devidamente anunciadas no BGP. Assim, o router_65000 saberá como retornar o pacote.
Veja o exemplo abaixo, onde usamos como origem um IP de link ponto a ponto:
router_65003#ping 10.10.0.10 repeat 5 source 10.1.18.2
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.10.0.10, timeout is 2 seconds:
Packet sent with a source address of 10.1.18.2
.....
Success rate is 0 percent (0/5)
Agora, usando como origem um IP de LAN (que está sendo anunciado no BGP), temos conectividade:
router_65003#ping 10.10.0.10 repeat 5 source 192.168.3.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.10.0.10, timeout is 2 seconds:
Packet sent with a source address of 192.168.3.1
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 2/2/4 ms
Router Reflector
Em ambientes com muitos roteadores iBGP, é comum surgir um problema de escalabilidade. Isso acontece porque o BGP impõe uma regra importante, roteadores iBGP não redistribuem rotas aprendidas de outros vizinhos iBGP. Em outras palavras, se um roteador recebe uma rota de um vizinho iBGP, ele não repassa essa rota para outros vizinhos iBGP, apenas para seus vizinhos eBGP.
Essa limitação existe para evitar loops de roteamento, mas cria um certo problema, para que todos os roteadores iBGP vejam todas as rotas, é necessário o Full Mesh. Essa exigência é conhecida como iBGP Full Mesh Requirement (como já vimos), e em um cenário com muitos roteadores, isso rapidamente se torna inviável.
O número de sessões cresce de forma exponencial. Com 10 roteadores, por exemplo, seriam necessárias 45 sessões iBGP. Com 100 roteadores, mais de 4.900 sessões. Gerenciar isso tudo é trabalhoso e consome muitos recursos. Para resolver esse problema, o BGP introduziu um mecanismo chamado Router Reflector (RR).
Um Router Reflector é um roteador iBGP que atua como ponto central de redistribuição, permitindo que outros roteadores (chamados de clientes RR) enviem e recebam rotas iBGP através dele. O RR quebra a regra da não redistribuição entre iBGPs, quando recebe uma rota de um cliente, ele reflete essa rota para os demais clientes e para seus vizinhos não-clientes, obedecendo certas regras de propagação.
É importante destacar que, embora o Router Reflector seja o responsável por distribuir as rotas, o tráfego de dados em si não precisa necessariamente passar por ele. O RR atua apenas no plano de controle (controle de rotas), e o encaminhamento de pacotes (plano de dados) pode seguir o caminho mais curto diretamente entre os clientes, conforme as rotas instaladas. Ou seja, o tráfego pode passar pelo RR, mas isso não é uma regra nem um requisito para o funcionamento correto.
Mesmo com todas as rotas corretamente propagadas pelo RR, se os clientes não tiverem conectividade IP entre si, o tráfego pode não alcançar o destino, ou seguir por caminhos ineficientes. Isso acontece porque o roteador, apesar de conhecer a rota, pode não ter como chegar ao next-hop informado. Ou seja, o uso de Router Reflector elimina a necessidade de full mesh no plano de controle (estabelecer sessões BGP), mas não substitui uma boa topologia no plano de dados.
Portanto, sempre que possível, garanta que os roteadores tenham conectividade entre si, especialmente entre os clientes do RR. Isso pode ser feito com uma Partial Mesh ou até mesmo uma Full Mesh, no quesito conexões físicas entre os roteadores.
Para nosso exemplo, vamos adicionar mais um router na rede (router_3_iBGP) e vamos fazer com que o router_20_iBGP seja o Router Reflector.
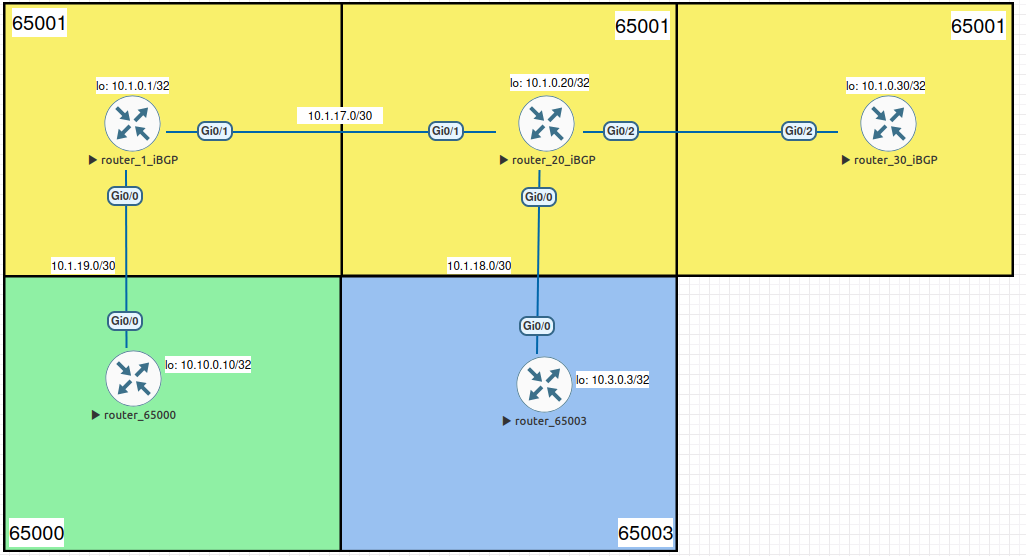
A imagem acima ilustra uma topologia de exemplo com Router Reflector, sendo ele o router_3_iBGP.
# router_3_iBGP:
enable
conf t
no ip domain lookup
!
hostname router_3_iBGP
!
interface Loopback0
ip address 10.1.0.30 255.255.255.255
!
interface GigabitEthernet0/2
description BGP com Router_20_65001
ip address 10.1.20.2 255.255.255.252
no shut
ip ospf 1 area 0
ip ospf network point-to-point
!
interface GigabitEthernet0/0
description LAN
ip address 192.168.30.1 255.255.255.0
no shut
!
router ospf 1
network 10.1.0.30 0.0.0.0 area 0
passive-interface GigabitEthernet0/0
!
end
wr
Agora vamos configurar o OSPF e interfaces no router_20_iBGP com o router_30_iBGP:
# router_20_iBGP:
enable
conf t
!
interface GigabitEthernet0/2
description BGP com Router_30_65001
ip address 10.1.20.1 255.255.255.252
ip ospf network point-to-point
ip ospf 1 area 0
!
interface GigabitEthernet0/3
description LAN
ip address 192.168.2.1 255.255.255.0
no shut
!
router ospf 1
no passive-interface GigabitEthernet0/2
passive-interface GigabitEthernet0/3
!
end
wr
Agora vamos configurar o iBGP com Router Reflector:
# router_20_iBGP:
conf t
!
interface GigabitEthernet0/3
ip address 192.168.2.1 255.255.255.0
no shut
!
no router bgp 65001
!
router bgp 65001
bgp router-id 10.1.0.20
bgp log-neighbor-changes
!
neighbor 10.1.0.1 remote-as 65001
neighbor 10.1.0.1 route-reflector-client
neighbor 10.1.0.1 update-source Loopback0
!
neighbor 10.1.0.30 remote-as 65001
neighbor 10.1.0.30 route-reflector-client
neighbor 10.1.0.30 update-source Loopback0
!
neighbor 10.1.18.2 remote-as 65003
!
address-family ipv4
network 192.168.2.0 mask 255.255.255.0
!
neighbor 10.1.0.1 activate
neighbor 10.1.0.30 activate
!
neighbor 10.1.0.1 next-hop-self
neighbor 10.1.0.30 next-hop-self
!
neighbor 10.1.18.2 activate
exit-address-family
!
end
wr
A diretiva route-reflector-client define que o vizinho iBGP será tratado como um cliente do Router Reflector. Isso permite que o router_20_iBGP redistribua rotas aprendidas de um cliente para os demais, sem precisar de sessões iBGP entre todos os roteadores.
O comando update-source Loopback0 garante que a sessão BGP use o IP da interface loopback como origem, aumentando a estabilidade da conexão, especialmente quando há múltiplos caminhos físicos.
Já o next-hop-self é importante para garantir que os clientes iBGP possam alcançar o next-hop das rotas aprendidas via eBGP. Como o RR não altera o next-hop por padrão, esse comando faz com que o próprio RR se torne o next-hop, evitando problemas de conectividade no plano de dados, principalmente quando os clientes não têm visibilidade direta entre si.